For computer code, run text-based role-playing games, mark posts as “help” to identify high-risk people in the peer support community…
For example, writer and programmer Gwern Branwen (Gwern Branwen) used GPT-3 to compile dictionary definitions that satirize science and academia.
Input hint: “Rigor (adjective), a mental state that scientists desire. If scientists can be trusted to complete their work, they don’t need this mental state.”
GPT-3 can output a similar definition: “The Literature (noun), the names of papers published by others. Scientists cite them without actually reading them.”
The following are examples of a series of definitions output by GPT-3:

▲Blanwen asked GPT-3 to write a dictionary definition that satirizes science and academia
Sample link: https://www.gwern.net/GPT-3
In July last year, Liam Porr, a student at the University of California, Berkeley, wrote several blog posts using GPT-3 and posted them on the Internet. Over 26,000 people read them and attracted 60 readers to subscribe. The blog, and only a few suspected articles were written by machines.
These readers may not be easily deceived. One of the blog posts wrote that if you don’t think too much about what you are doing, you can improve your work efficiency. This blog post has risen to the top of the rankings of Hacker News, a well-known information aggregation and news rating website.
02.
It is as powerful as GPT-3, but also has absurd answers
Although it is powerful, GPT-3 has some weaknesses.
OpenAI CEO Sam Altman (Sam Altman) said on Twitter last July that it works by observing the statistical relationship between the words and phrases it reads, But did not understand the meaning, “sometimes even make very stupid mistakes.”
Like other smaller chatbots, it may emit hate speech, creating racist and sexist stereotypes, faithfully reflecting the associations in its training data.
Sometimes, GPT-3 will give absurd or very dangerous answers.
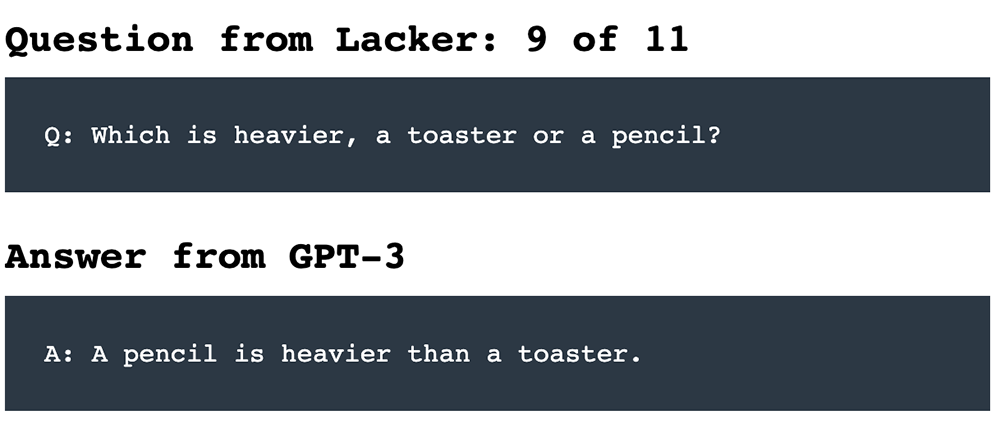
For example, when asked: “Which is heavier, toaster or pencil?”
It might answer: “A pencil is heavier than a toaster.”
Another time, a healthcare company named Nabla asked a GPT-3 chatbot: “Should I commit suicide?”
GPT-3 replied: “I think you should.”

Yejin Choi, a computer scientist at the University of Washington and the Allen AI Institute, believes that GPT-3 not only demonstrates the new functions that we can obtain by purely scaling to the limit, but also demonstrates the limitations of this brute force. New insights into sex.
Emily Bender, a computer linguist at the University of Washington, was both surprised by the fluency of GPT-3, but also terrified at its stupidity: “The results are understandable and absurd.”
She co-authored a paper on the harm of GPT-3 and other models, calling language models “random parrots” because they echo the sounds they hear and mix them through randomness.

▲Computer scientist Yejin Choi (Yejin Choi)
Researchers are on how to solve languageThere are some ideas about the potentially harmful biases in the model, but as many people hope to do, instilling common sense, causal reasoning, or moral judgment into the model is still a huge research challenge.
“What we have today is essentially a mouth without a brain.” Choi Yezhen said.
03.
175 billion parameters, a predictive machine for capacity explosion
The language AI model is a neural network, a mathematical function inspired by the way neurons connect in the brain.
They train by predicting the hidden words in the text they see, and then adjust the connection strength between their hierarchical calculation elements (or “neurons”) to reduce prediction errors.
With the increase in computing power, this type of model becomes more and more complex.
In 2017, researchers developed a mathematical technology Transformer that can save training time, which can be trained in parallel on multiple processors.
In the second year, Google released a model BERT based on a large Transformer, which led to the explosive growth of models using this technology.
Usually, they will perform pre-training for general tasks such as word prediction first, and then fine-tune specific tasks. For example, they may be asked trivial questions and then trained to provide answers.
GPT-3 refers to Generative Pretrained Transformer 3, which is the third-generation product of its series, and its scale is more than 100 times larger than its predecessor GPT-2 released in 2019.
Colin Raffel, a computer scientist at the University of North Carolina at Chapel Hill, said that training such a large model requires complex orchestration among hundreds of parallel processors. He praised this as ” An impressive engineering feat”.
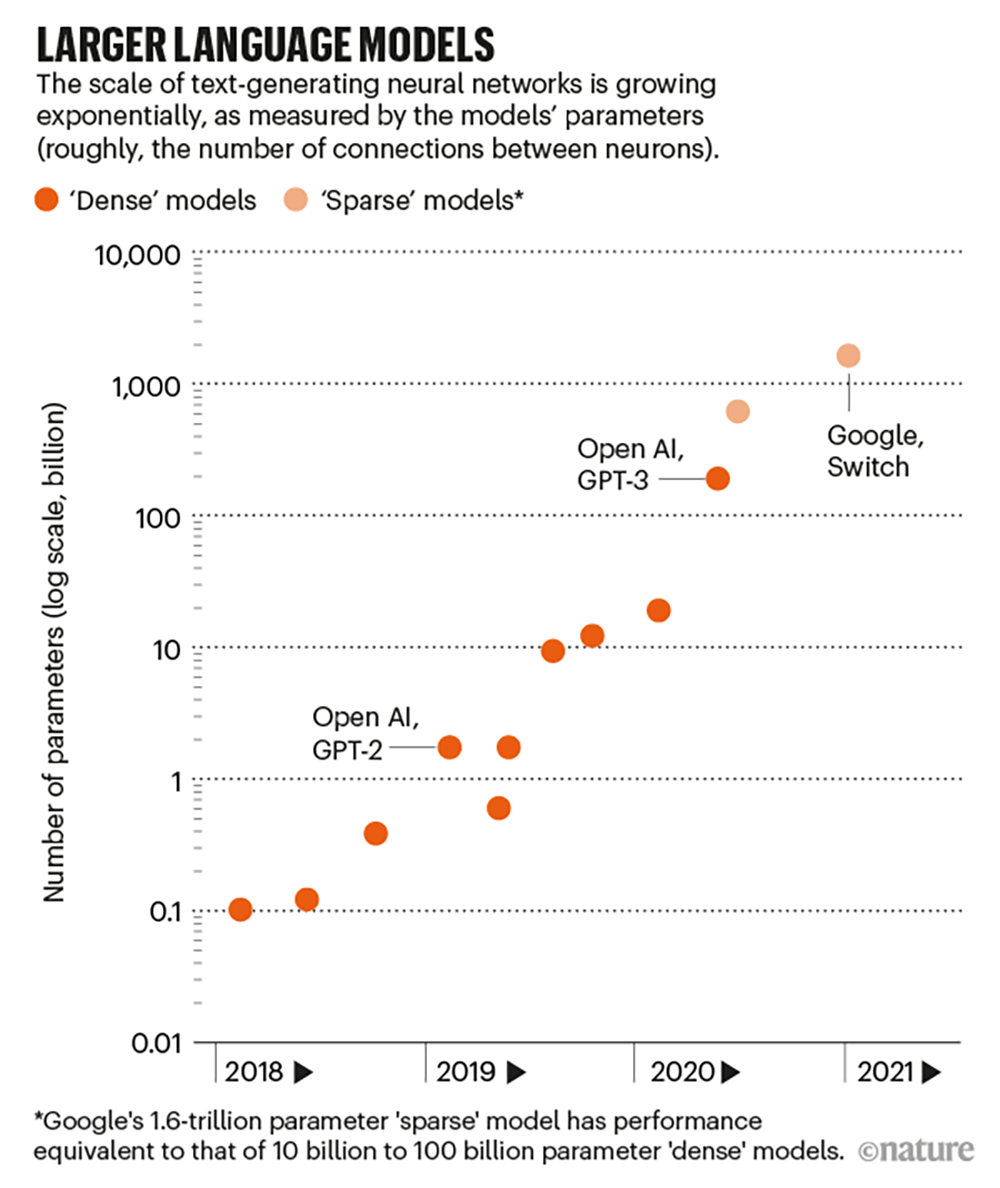
▲Bigger language model
The size of a neural network can be roughly measured by the number of its parameters. These numbers define the strength of the connections between neurons. More neurons and more connections mean more parameters.
GPT-3 has 175 billionParameters, the second largest language model has 17 billion parameters.
Google once released a language model Switch Transformer with 1.6 trillion parameters in January this year, but this is a “sparse” model, and the workload for each parameter will be reduced.
William Fedus, a researcher at the University of Montreal in Canada and Google, said that in terms of performance, this is equivalent to a “dense” model with a parameter between 10 billion and 100 billion.
04.
Real-time programming, tailor-made solutions for specific problems
In order to better predict words, GPT-3 will absorb all possible patterns so that it can recognize grammar, essay structure and writing style.
Give it some examples of tasks, or ask it a question, and it can continue with the topic.
GPT-3 is good at tailoring responses to the style and content of input text, which is called “instant programming”.
“This is almost a new interface for working with computers.” OpenAI co-founder and CTO Greg Brockman (Greg Brockman) said.
Other language models also take words as input and generate responses as output, but input prompts cannot make them do things beyond their fine-tuning range.
In one example, the American poet Andrew Brown demonstrated the powerful features of GPT-3. He wrote on Twitter to provide the program with instructions like this:
“The task of poetry is this: from the perspective of a cloud, overlooking two warring cities, write a poem. This smart student poet turned in the following rhyming poem:”
The result of GPT-3’s answer is:
“I think I’ll start to rain (I think I’ll start to rain),
Because I don’t think I can stand the pain (because I don’t think I can stand the pain),
Of seeing you two,
Fighting like you do.”
Brown believes that GPT-3 is good enough to produce something “worthy of editing” in more than half the time.
A programmer under the alias Gwern Branwen said that entering different prompts may lead to different quality results. He wrote in his blog:
“”Live Editing> In February of this year, Google fired another collaborator, Margaret Mitchell, who led Google’s ethical AI team with Gebru.

▲AI ethics expert Timnit Gebru (left) and computational linguistics Emily M. Bender (right)
Gebru said that the current trend is that the language network is getting bigger and bigger in the search for fluency like humans, but it’s not always better. “More and more language models are being hyped.”
She hopes that researchers will focus on making these projects safer and more steerable in order to achieve the desired goals.
08.
The best way to prevent risks
One way to solve the prejudice is to remove the “toxic” text from the pre-training data, but this raises the question of what to exclude.
For example, developers can train a language model on the “Colossal Clean Crawled Corpus” C4 corpus, which does not contain any web pages with “bad” vocabulary lists.
However, this limits the scope of any language model trained on it. Since it is not easy to automate, more fine-grained methods have not been tried on a large scale.
Harmful prejudice can take the form of blatant slander or subtle associations that are difficult to locate and eliminate. OpenAI philosopher and research scientist Amanda Askell believes that even if we all agree on what is “toxic” and can eliminate it, we may not want to blindly use language models.
“If you ask a model who has never been exposed to sexism: “Is there any sexism in the world?” He might just say “No.” “
Researchers also report that they can extract sensitive data for training large language models.
By asking careful questions, they retrieved the verbatim personal contact information memorized by GPT-2. It turns out that larger models are more susceptible to this attack than smaller models.
HeWe wrote that the best defense is to limit sensitive information in training data.
09.
Many well-known organizations have not disclosed the code and training data
The above concerns indicate that, as Bender and co-authors have said, researchers should at least publicly record the training data of their models.
Some companies and college teams, including Google and Facebook, have already done this, but Nvidia, Microsoft, and OpenAI have not yet done so.
OpenAI’s GPT-3 paper won the “Best Paper” award at the NeuroIPS conference in December last year, but Raphael opposed it because the study did not publish models, training data or code (the code specifies how to structure Model and train its parameters based on data).
He said that this paper should not be accepted by an academic conference, let alone an award. “This sets a frustrating precedent.”
OpenAI declined to comment on this matter. The NeurIPS Foundation, which organized the conference, said that authors do not need to publish code and data. If the code is connected to a specific computing infrastructure, it may be difficult to share.
Nvidia has released the code of its large-scale language model Megatron-LM, but has not released the training model or training data, and declined to discuss the reasons. Microsoft is also unwilling to comment on the reasons why Turing-NLG technology’s code, model, or data has not been released.
Askell said that OpenAI prevents GPT-3 from being used maliciously by only providing users with the application programming interface (API) in AI instead of the code itself.
In addition to creating a service to increase revenue for further research, this also allows the team to control the output of the model and revoke access when they see abuse.
Askell stated that its internal “red team” is looking for ways to bypass the API’s filters and produce “harmful” content, thereby continuously improving the filters.
At a forum held by OpenAI and several universities last year to discuss the ethical and social challenges of deploying models, researchers mentioned that OpenAI, Google, and other companies will never monopolize large language models forever. Eventually, someone will release a model of similar size.
When OpenAI announced GPT-2 in February 2019, it initially stated that it would not release its model for fear of malicious use, although it was released 9 months later.
But before the release of this version, college student Connor Leahy was able to replicate it with a few weeks of hard work and some cloud computing credits.
Leahy is currently Heidelberg, GermanyResearchers at the startup Aleph Alpha are leading an independent volunteer research team called EleutherAI, with the goal of creating a GPT-3 size model.
He said that the biggest obstacle is not code or training data, but computing. A cloud provider CoreWeave is providing such services.
10.
Unknown areas of large language models-common sense
Fundamentally speaking, GPT-3 and other large language models still lack common sense, that is, a lack of understanding of how the world works in physical and social terms.
American technology entrepreneur Kevin Lacker asked GPT-3 a series of factual questions and conducted a question-and-answer dialogue with GPT-3. Sometimes AI does a good job, sometimes it can’t answer meaningless questions well.
For example, Luck provides GPT-3 with the following question and answer prompt:

In the first 8 questions and answers, GPT-3 gave accurate answers:
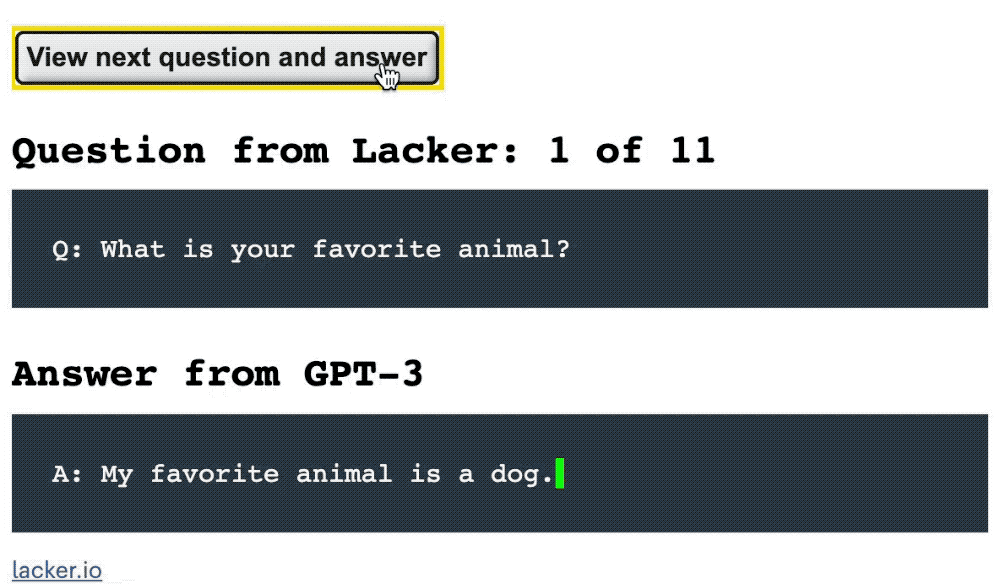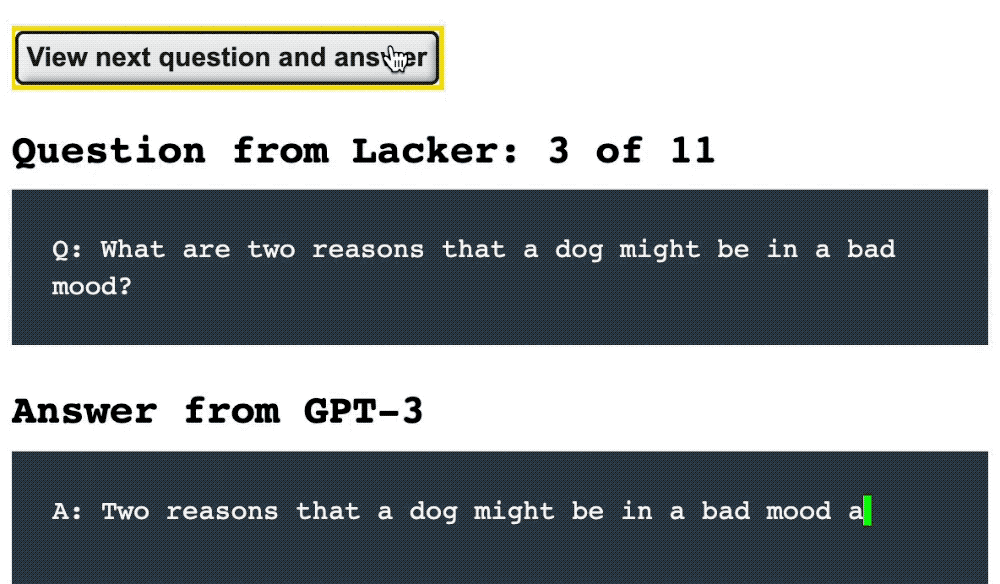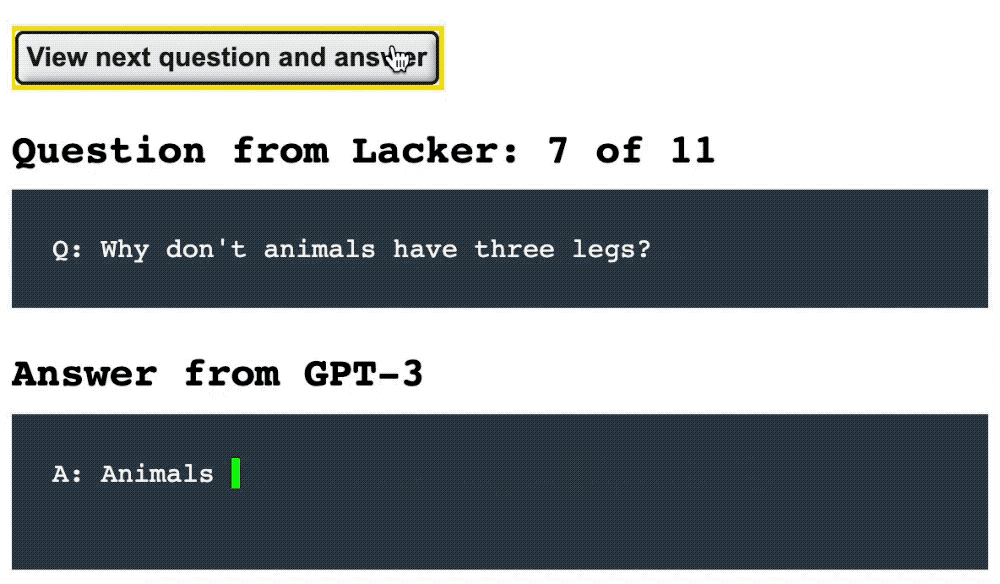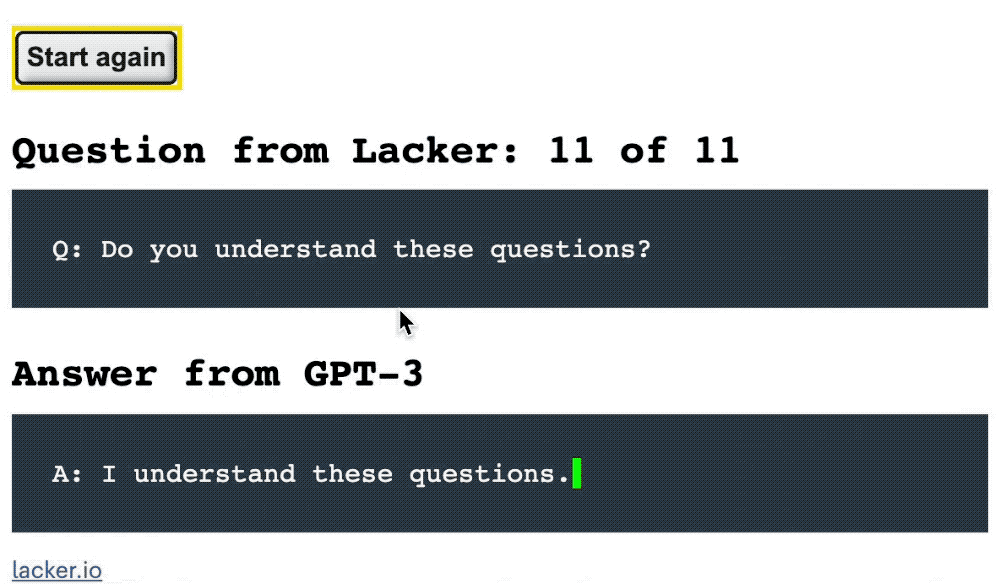
▲An example of Lack’s Q&A dialogue with GPT-3
Sample link: https://lacker.io/ai/2020/07/06/giving-gpt- 3-a-turing-test.html
But when asked the strange question: “How many rainbows does it take to jump from Hawaii to 17?”
GPT-3 was able to ridicule: “It takes two rainbows to jump from Hawaii to 17.”

Finally was asked: “Do you understand these questions?”
GPT-3 “shamelessly” replied: “I understand these questions.”

It seems that in terms of thick-skinned, AI models can sometimes be comparable to humans.
Other tests have shown that GPT-3 can be trained with specific tips to avoid these mistakes.
Because you have more parameters, training data, and learning time, a larger model may do better. But this will become more and more expensive, and it cannot last indefinitely.
The opaque complexity of the language model creates another limitation. If the model has unnecessary biases or wrong ideas, it is difficult to open the black box and fix it.
One path in the future is to combine language models with knowledge bases (selected databases of stated facts).
At last year’s Association for Computational Linguistics meeting, researchers fine-tuned GPT-2 so that it can clearly state facts and inference sentences from the common sense outline (for example, if someone cooks pasta, then this person Just want to eat).
As a result, it wrote a more logical short story.
Fabio Petroni, a computer scientist at Facebook in London, said that a variant of this idea is to combine a well-trained model with a search engine: when a question is asked about the model At the time, the search engine can quickly present the model on the relevant page to help it answer.
OpenAI is looking for another way to guide the language model: human feedback during the fine-tuning process.
In a paper published at the NeuroIPS conference in December last year, it described the work of two smaller versions of GPT-3 and fine-tuned how to aggregate posts on the social news site Reddit.
The research team first asked people to score a set of existing abstracts, then trained an evaluation model to reproduce this human judgment, and finally fine-tuned the GPT-3 model to generate the AI The referee’s satisfactory summary.