This algorithm can improve picture lighting, you deserve ~
Editor’s note: This article is from the micro-channel public number “door Ventures” (ID: thejiangmen), Author: SIGGRAPH Asia 2020, compiling: T.R.
In the process of portrait photography and film shooting, lighting plays a very important role. In order to achieve better rendering and post-production, it is necessary to estimate the lighting information of the characters in the image. Inspired by the cues of cast shadows and specular reflections, Google researchers have proposed a technical means of learning high dynamic omnidirectional lighting from a single RGB image under arbitrary lighting conditions, and paired photos of people under different lighting conditions. The model is trained.
Experiments show that this method can effectively restore high-performance light effects for photos of people with multiple skin tones. Under the effect of continuous lighting, virtual backgrounds or cartoon characters can also be added to portrait photos. The lightweight architecture also makes it possible to run on the mobile terminal.
For more details, please refer to the original paper:

Thesis link:
https://arxiv.org/pdf/2008.02396.pdf
Project homepage:
https://augmentedperception.github.io/facelight/
Related reference:
https://augmentedperception.github.io/deeplight/
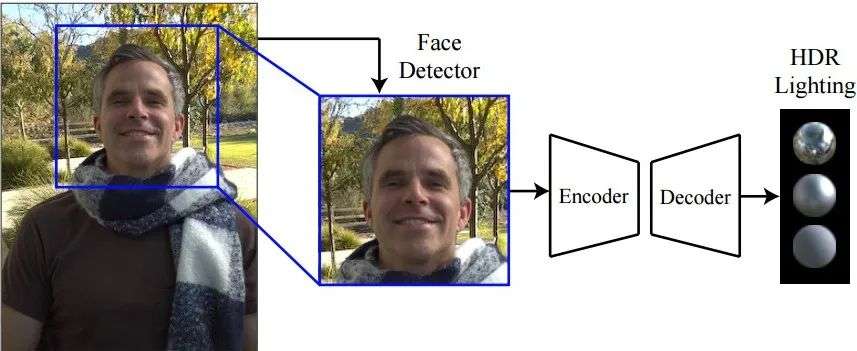
High dynamic lighting estimation based on a single image
For experienced photographers, the light situation during shooting can be obtained not only from the diffuse reflection of the skin, but also from the direction and range of the cast shadow, The intensity and position of the specular reflection are obtained. Inspired by this experience, the researchers proposed a model that can achieve reverse illumination from portraits, without any specific skin reflection model assumptions, and can also estimate the omnidirectional high dynamic range lighting situation in the environment.condition. This technology can obtain lighting information with higher frequency details, making more realistic portrait rendering and ARi visual effects possible.
In order to train this model, the researchers constructed a huge data set containing portraits and corresponding lighting conditions. The data set contains basic data of 70 people under 331 lights, and about one million portrait data sets containing indoor and outdoor lighting environments generated by rendering technology. Let us learn more about the implementation process of this technology from the aspects of data set, model architecture and experiment.
Training the model requires a large number of portrait photos with markings of lighting conditions, but it is almost impossible to collect such a large data set in reality, so the researchers adopted an image-based digitally driven heavy lighting technology to Synthesize portrait photos with lighting annotations, and render realistic images by appropriately capturing complex light transmission phenomena. Under the theoretical framework of the reflected field, people can obtain the subject image under re-illumination through the dot product of the reflected field and the HDR ambient light.
In order to record the reflection field of the person, the researchers used 331 LED lights installed in the sphere to shoot. The reflection field is recorded through a series of reflection base images. Each time you turn on an LED light to shoot and record an independent Illumination results (One-Light-At-a-Time, OLAT), and use 6 cameras to record images of people at different angles.

The shooting results under different lighting
The 35mm lens is used to shoot busts from different angles, and the 50mm lens is used to shoot the details of the face.

The study invited 70 people of different ages, skin colors, and genders to shoot, and recorded nine different expressionsIn the end, 3780 sets of imaging results under 331 illumination sequences were obtained.

Because it takes six seconds to obtain the complete OLAT sequence of the object, the target will inevitably move to a certain extent during the shooting. In order to solve this problem, the researchers used optical flow technology to align the images, adding a pair of uniform illumination “tracking” frames every 11 OLAT frames to ensure that the brightness of the optical flow is constant. This step can ensure the sharpness of image features during the relighting operation, so that the aligned OLAT images can be linearly combined.
Using the two cameras directly in front, the researchers also obtained the mask of each subject so that they could be rendered into the new environment. First, six LEDs are used to uniformly illuminate the gray background material, and the characters will not be illuminated; at the same time, the complete background without people is shot under the same conditions. In this way, the mask can use the image taken the first time to separate the clean background image from the second shot.
High dynamic environment capture. In order to relight the subject using the captured reflection field, the researchers collected a large-scale data set of a highly dynamic environment to drive the deep learning algorithm. Here we mainly use video-level image capture technology to obtain nearly 1 million indoor and outdoor data sets.

As shown in the image above, the captured image contains scatter, frosted silver and mirrored reference spheres. These three balls can effectively reflect different lighting cues in the environment. Among them, the mirror ball reflects the omnidirectional high-frequency information, but will ignore the brighter light source, causing the intensity and color to change; and the diffuseness of the Lambertian BRDF is similar. The reflective ball can be regarded as a low-pass filter, capturing fuzzy but relatively complete scene lighting cues. Different from previous work, this study needs to obtain real HDR lighting information to relight the characters, and it is necessary to explicitly improve the quality of the three balls to estimate the HDR lighting conditions of the environment.
In the givenAfter capturing the three sphere images with reflection conditions (there may be missing pixels), the researchers hope to obtain reasonable results by solving the HDR lighting. First, use the aforementioned illumination system to record the reflection fields of the diffuse reflection ball and the scattering silver ball, and convert the radiation reference image to the same radiation space, which is normalized by the color of the incident light source . Subsequently, the reflection reference image is projected onto the mirror sphere (equal area projection based on the Lambertian azimuth angle), and energy is accumulated for each input image to form a reflection field. For the image captured by the mirror ball, if there is no missing, the reflectance is used to restore the scene lighting; if there is a missing, the corresponding result is solved by the reflection model and the least square method. The HDR reflection field can be reconstructed through a series of complex algorithms.

In the figure above, the upper part is the benchmark LDR image, and the lower part is the sphere lighting record rendered with the estimated HDR. For more detailed derivation, please refer to the fourth part of 3.1 of the article.
After recording the reflection field for each task and estimating the HDR lighting conditions, the researchers can re-illuminate each character in the new scene to generate large-scale training data. Using the background image containing three ambient light detectors, researchers can render the portraits acquired in the recording into a rich background environment. The following figure shows the process of obtaining natural images in the new background environment.

The above figure respectively shows the background image, the corresponding HDR lighting results, the shooting results of the subject and the use of environmental image As a result of the lighting, the final result is a natural synthesis of the mask and the background image.
In order to use the data more effectively, the researchers also added face detection capabilities to provide certain face detection for the input dataFrame to help the model learn better.

The synthetic training data set cuts the face detection part, and the upper right corner is the HDR lighting result.
Network architecture and experimental results
The input image of the network is a 256×256 pixel normalized image and the corresponding LDR lighting. The codec architecture is used for training, and the final output is in logarithmic space 32×32 mirror ball HDR image to represent omnidirectional illumination. At the same time, an auxiliary discriminator branch is used to increase the counter loss and strengthen reasonable high-frequency illumination estimation. In the final training, multi-scale image re-illumination rendering loss and counter loss are introduced to guide the network training.
After the training, the researchers first compared the estimated environmental lighting information with a variety of algorithms. It can be seen that the recovery result of this algorithm is even better. For authenticity.

At the same time, the researchers also relighted the characters based on the estimated lighting results, compared the rendering results of different components, and used the resulting lighting for rendering New characters.

In the figure above, the first and second columns are the input images and the corresponding reference lighting; the third column is the predicted lighting results; the fourth column It is the result of re-rendering using the predicted lighting. The last three columns are the result of rendering the new character in the same environment using the previous lighting.
In addition, the figure below shows that multi-scale loss can effectively improve the accuracy of the final ambient light estimation, and the result of the lowest mirror ball estimation has become significantly clearer.

Next, let’s look at some of the environmental lighting results predicted by the rendered image. It can work stably on different skin tones, expressions, and head poses.

In real outdoor scenes, high-performance light estimation can also be achieved, and new tasks can be rendered in the same environment.

As shown in the figure, the first column is the actual input image, the second column is the estimated lighting result, and the third column is the rendering of the digital character to the corresponding Results in the environment. You can see that the lightThe shadow effect is very realistic.
In addition, with the estimated ambient light, some special effects can also be rendered very realistic. The picture below shows the effect of rendering a virtual balloon as a background in a selfie, just like real.
