The next great AI technology has come out of the laboratory.
Editor’s note: This article is from the WeChat public account “Machine Power” (ID: almosthuman2017).
Many people’s impression of reinforcement learning is still playing games. For example, the famous “Alpha Dog”, Deepmind and OpenAI have released “StarCraft” and “Warcraft 2” game systems that can defeat top human players.
In fact, reinforcement learning systems are transitioning from research laboratories to more influential practical applications. Reinforcement learning can learn the best strategy to control large complex systems, such as manufacturing plants, traffic control systems (road/train/aircraft), financial assets, robots, etc. Self-driving car companies like Wayve and Waymo are using reinforcement learning to develop car control systems.
We have seen how fast the technological environment changes. A few years ago, deep learning entered the business field. Today, 30% of high-tech and telecommunications companies, and 16% of companies in other industries have embedded deep learning capabilities. When executives understand the potential of reinforcement learning, many organizations will follow a path similar to the New Zealand Emirates team-first, implement more traditional techniques to solve problems, and then apply reinforcement learning to improve performance to levels that were previously unattainable .
A defending champion and AI “Sailor”
The America’s Cup Regatta is one of the oldest events in the international sports world and the most coveted award in competitive sailing competitions. The America’s Cup has always attached great importance to technology and innovation. Each ship is equipped with a computer simulator. The team that has the best simulator and makes the most effective use of it will gain a competitive advantage.

The America’s Cup Regatta, one of the most money-burning sports in the world.
The New Zealand Chiefs are no exception. In 2010, the team built the most advanced digital simulator at the time to test the ship design without actually building it. This is the key for the team to win the Copa America in 2017.
However, the limitations of the simulator are also obvious.
On the one hand, multiple sailors are required to optimize operations. The problem is that sailors need training, travel, and competition, and it is difficult to allocate more time to optimize design work. Designers can only iterate new designs in the absence of simulator performance data, and test their best ideas in batches when the sailors have time.
The other partyOn the other hand, the performance of sailors may be different in different tests, just as human performance is usually different. It is difficult for designers to know whether the small improvement in ship response is due to design adjustments or due to differences in human testing.
When preparing for the 2021 game, the Chiefs boldly imagined that if they had a qualified “AI sailor” to replace them to operate the simulator. As a result, they and their partners used reinforcement learning to successfully train an AI sailor to drive a simulator to help optimize the key design process.
For example, hydrofoil. These wing-like structures are attached to the hull of the ship so that the ship floats on the water, which can make the ship speed more than 50 knots (60 miles or 100 kilometers per hour), which is very important.

The Emirates Team of New Zealand used reinforcement learning to test the hydrofoil design.
Reinforcement learning allows robots to learn dynamically and obtain higher accuracy through continuous feedback. In the beginning, “AI Sailor” is Xiaobai, who knows nothing. Through trial and error learning of countless variables-wind speed, direction, adjustment of 14 different sails and ship control-it has been perfected again and again.
In the first two weeks, “AI Sailor” drove in a straight line, with a tailwind and tailwind. After mastering the basic knowledge, he gradually mastered more complex sailing skills. The turning point came about eight weeks later, when the “AI Sailor” began to defeat the sailor in the simulator, which became an ideal way to test the deformation of the hydrofoil.
With the “AI Sailor”, the design process has been accelerated ten times. Thousands of hydrofoil design concepts can be evaluated instead of hundreds of award-winning designs. You can understand how such designs are The possible performance on the water greatly reduces the design cost.
Finally, the team was able to test more hull designs at an exponential speed and achieved a performance advantage, defending the fourth cup championship.

II Reinforcement learning out of the laboratory
Several large technology companies, including Google, are strengtheningA large amount of investment has been made in the research of chemical learning-for example, in 2015, Google acquired Deepmind for 400 million pounds (approximately US$525 million). So far, most familiar cases come from board games (Go, Chess, etc.) and video games.
Reinforcement learning is a powerful artificial intelligence technology. Unlike other types of machine learning, the algorithms used in reinforcement learning (usually used to train artificial intelligence agents or robots) usually do not rely solely on historical data sets (whether labeled or unlabeled) to learn to make predictions or perform tasks. Like humans, they learn through trial and error.
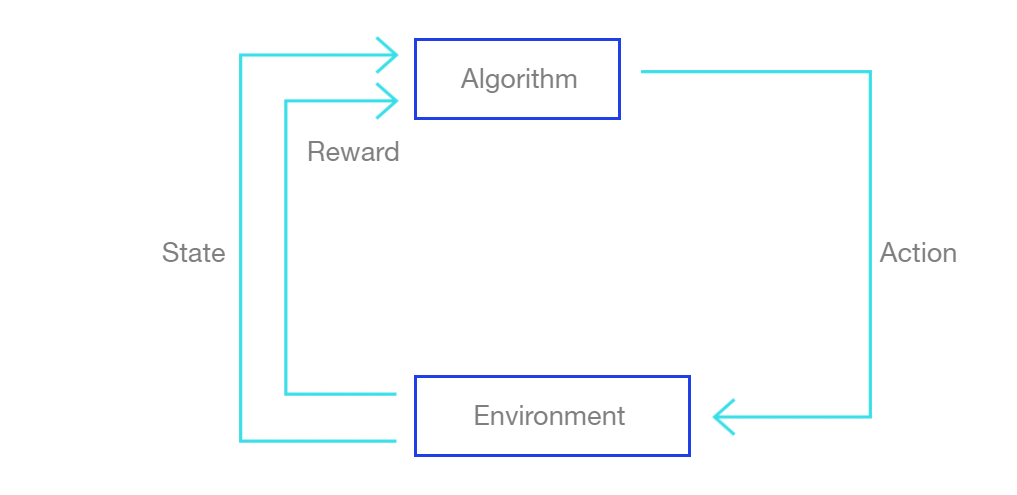
The basic logic of reinforcement learning.
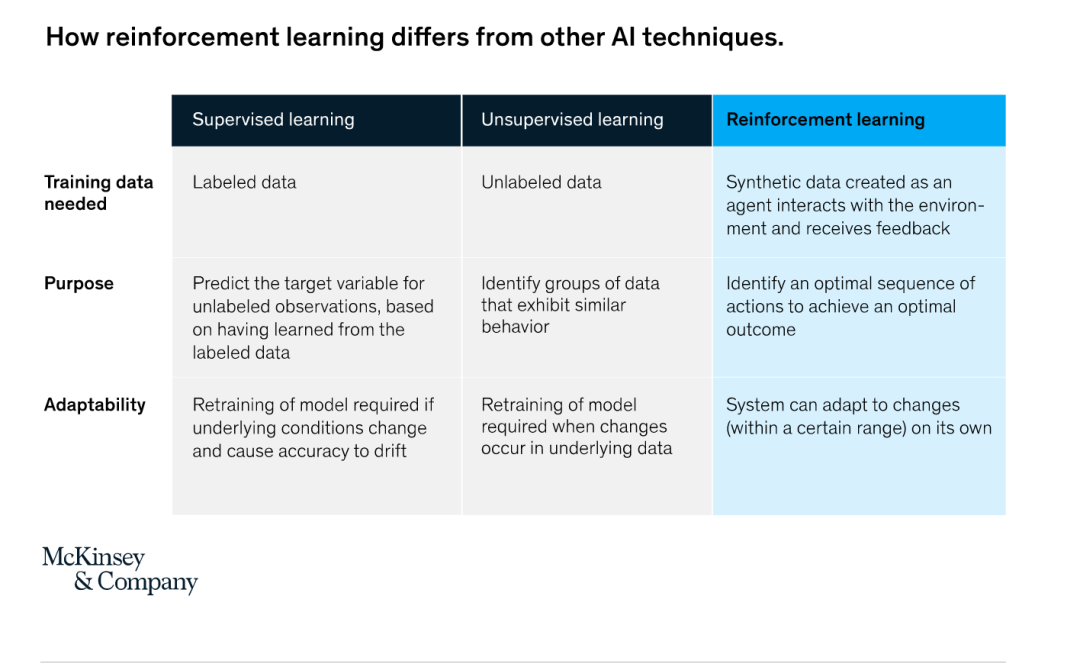
How does reinforcement learning differ from other AI technologies.
In the past few years, the technology has matured, is highly scalable, and can optimize decision-making in complex and dynamic environments. In addition to accelerating and improving design, reinforcement learning is increasingly integrated into a wide range of complex applications:
For example, self-driving car companies like Waymo are using reinforcement learning technology to develop control systems for their cars; recommending products in systems with rapidly changing customer behaviors and preferences; predicting time series under highly dynamic conditions; solving complexities Logistics issues, including packaging, routing and scheduling; and even accelerate clinical trials and impact analysis of economic and health policies on consumers and patients.
Many startups are also offering reinforcement learning products. For example, it is used to control manufacturing robots (Covariant, Osaro, Luffy), manage production planning (Instadeep), corporate decision-making (Secondmind), logistics (Dorabot), circuit design (Instadeep), control autonomous vehicles (Wayve, Waymo, Five AI ), control drones (Amazon), run hedge funds (Piit.ai), and pattern recognitionMany other applications that the AI system cannot achieve.
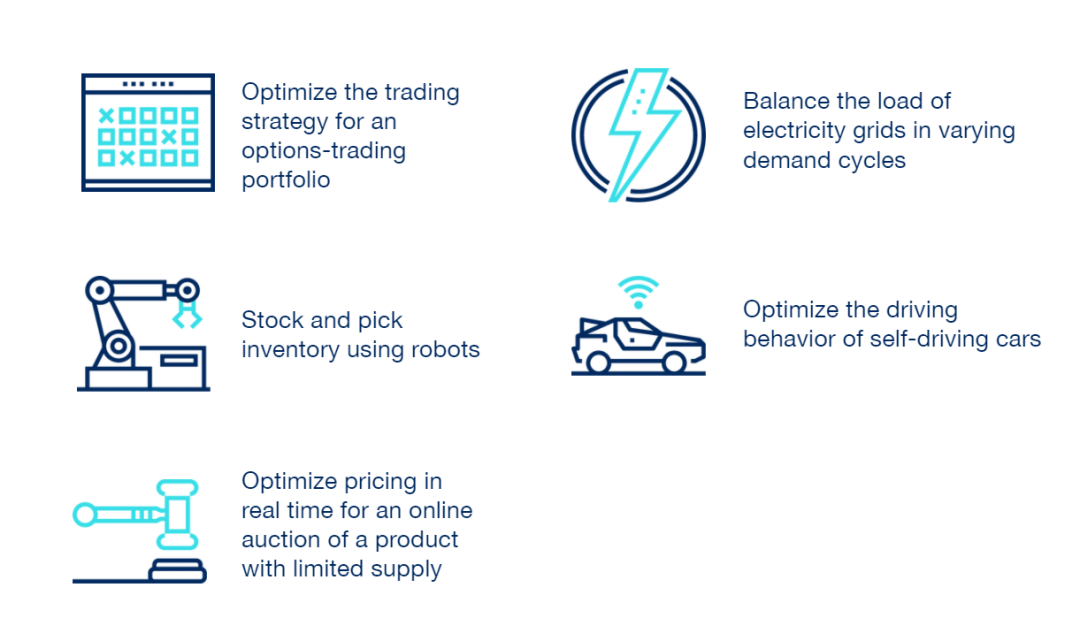
Application scenarios of reinforcement learning.
In any case, at this point in time, the future of reinforcement learning in the real world does look very bright. We can give a simple example to distinguish between reinforcement learning and AI pattern recognition.
Suppose we are using artificial intelligence to help run a manufacturing plant. AI pattern recognition is used to detect any product defects and ensure quality assurance. The reinforcement learning system will calculate and execute the strategies that control the manufacturing process itself.
For example, by deciding which production line to run, controlling the machine/robot, deciding which product to produce, and so on.
This system will also try to ensure that the strategy is optimal, because it maximizes some profit indicators-such as output-while maintaining a certain level of product quality.
The calculation problem of the optimal control strategy solved by reinforcement learning becomes very difficult due to some subtle reasons (often much more difficult than pattern recognition).
Three types of application scenarios of reinforcement learning
The core challenge of the defending champion case is to solve a complex business problem in a dynamic environment. In this environment, variables change in unpredictable ways, the ideal final state is only loosely defined, and the only way for the system to understand its environment is to interact with the environment.
This situation is similar to the problems faced by retailers, manufacturers, utility companies, and many other industries.
For example, although retailers can reasonably expect past consumer behavior to reflect future preferences, in their current world, purchasing patterns and preferences are evolving rapidly—especially the COVID-19 pandemic continues to redefine life ; Manufacturers and consumer packaging companies are under pressure to establish dynamic supply chains that take into account climate, political and social changes anywhere in the world.
Each challenge represents a complex and highly dynamic optimization problem. With correct data and feedback loops, it is very suitable to be solved by reinforcement learning.
For many possible actions and paths, the appeal of reinforcement learning is that AI agents do not need to be explicitly programmed. Because it learns from examples and teaches itself through trial and error, it can come up with novel, adaptive solutions, usually faster than humans.
For example, in the case of the Emirates Team of New Zealand, multiple designs can be tested at the same time using AI, but human sailors will never be able to test in parallel. This is the fleet that completed the comparison at a faster speed. More design tests before.
In a broad sense, some recent applications of reinforcement learning fall into three categories: accelerating design and product development, optimizing complex operations, and guiding customer interactions.

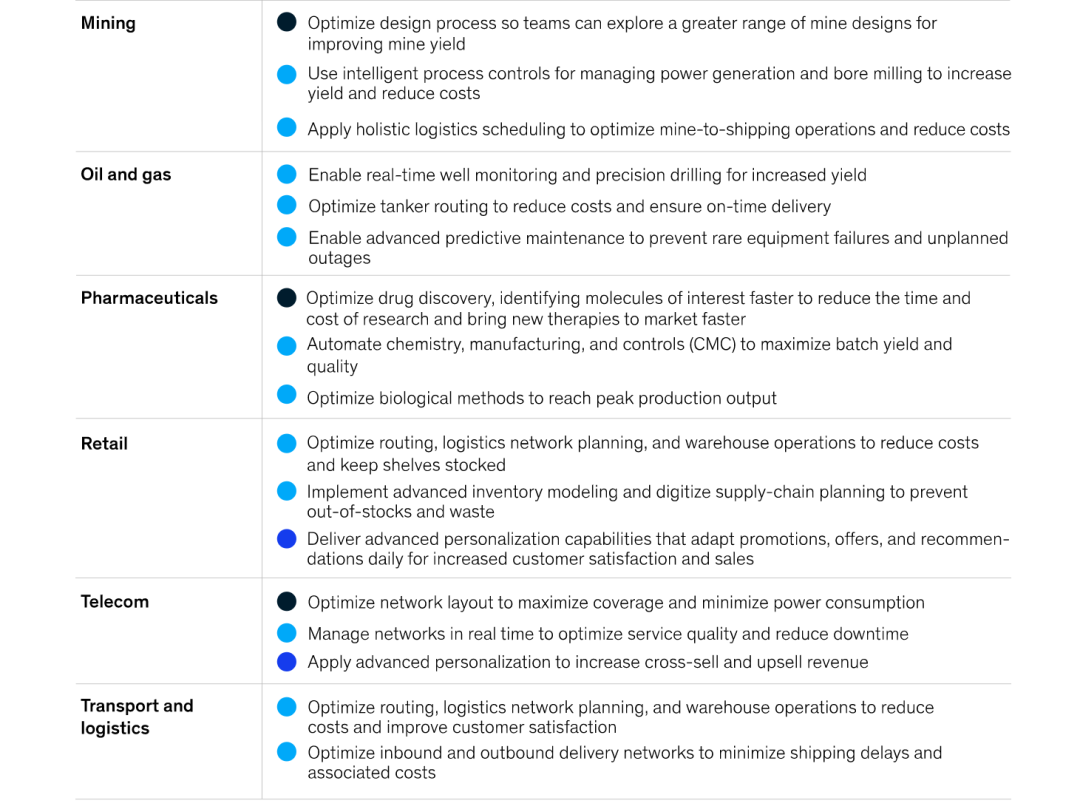
The main industrial applications of reinforcement learning.
First, accelerate design and product development. Reinforcement learning can improve the development of products, engineering systems, manufacturing plants, refineries, telecommunications or utility networks, and other capital projects.
For example, mining companies can explore a wider range of mine designs compared to other artificial intelligence technologies currently used to increase production.
An automobile manufacturer is already exploring how to train agents through reinforcement learning to test more regenerative braking ideas in new electric vehicles to optimize the design of noise, vibration, and heat.
Secondly, optimize complex operations. The ability of reinforcement learning to solve complex problems gives it the potential to optimize complex operations. Initially, we saw three main applications of reinforcement learning in this field.
First of all, reinforcement learning can help organizations identify the right actions and take events across the value chain. For example, a transportation company can optimize travel routes in real time according to changes in traffic, weather, and safety conditions; under conditions such as daily or even hourly demand and exchange rate fluctuations, and different transportation routes, food manufacturers can optimize their products on a global scale Distribution.
It can also help the team manage complex manufacturing processes. For example, it allows the team to monitor production in real time, simulate different scenarios and update key parameters to dynamically increase production. Those manufacturers that have used machine learning to minimize product defects can now use reinforcement learning to expand their knowledge to prevent rare residual defects from appearing intermittently. There seems to be no common root cause.
Finally, reinforcement learning can power autonomous system controllers. For example, by continuously monitoring and adjusting the working temperature of the equipment to ensure the best performance, or running a robotic arm in a production workshop.
Furthermore, tell each customer the best course of action for the next step. When integrated into a personalization and recommendation system, reinforcement learning can help organizations understand, identify, and respond to changes in user tastes in real time, personalize information, and adjust promotions, offers, and recommendations every day. Such as Baidu and Kuaishou.
Fourth toward widespread deployment
Of course, implementing reinforcement learning is a challenging technical pursuit. Simply put, a successful reinforcement learning system requires three elements:
A well-designed learning algorithm with reward function. Reinforcement learning agents learn by trying to maximize the rewards for the actions it takes;
A good algorithm with a properly defined reward function enables an actor to make complex decisions-for example, the action taken now may not be optimal in the short term, but will be rewarded generously in the long term ;
A learning environment. Usually, the learning environment involves a simulator or digital twin, which replicates the real environment in which the agent will operate, and provides a training ground for the agent. However, in some cases, the learning environment may be a digital platform, such as a product ordering system, in which an artificial intelligence agent can perform the same (or similar) tasks repeatedly and quickly receive feedback on the success of its actions.
Computer power. Training agents require a lot of computing resources and specialized infrastructure. These infrastructures can scale out thousands of distributed training jobs. Even if they run in parallel, these jobs usually require thousands of hours of computing time.
A few years ago, the cost and complexity of building and training these systems were beyond the reach of everyone except a few technology leaders. However, major technological advancements to address these obstacles have made it easier for more companies to gain access to reinforcement learning, and the continued development of required tools has enabled each company to quickly master the technology.
Costs are becoming manageable. The latest iterations of reinforcement learning algorithms are significantly improving training efficiency and greatly reducing computational costs. At the same time, the cost of the computer itself has dropped significantly. Companies can now access specialized systems in the cloud and pay only for the content they use.
In addition, new tools and strategies enable teams to manage the calculations they use. For example, the resource allocation and development tools now available enable the team to determine the cheapest (or most efficient) calculation for a given purpose at any given time.
In other words, in order for this technology to be more widely used, the computational cost of reinforcement learning tasks needs to be further reduced. We expect this to happen in the near future for several reasons, including increasing competition among cloud vendors.
The cloud-based framework solves the complexity of the system. Cloud providers are also working hard to deliver pre-packaged, enterprise-level frameworks that can be deployed in a pipeline manner, including the necessary tools, protocols, application programming interfaces (api), open source libraries (such as RLlib), and other elimination Techniques for manual coding and integration work.
For example, the framework allows teams to run training on dozens of systems with a single line of code instead of writing this functionality from scratch. In the New Zealand defending case, the development team borrowed from these frameworks as much as possible and then focused on value-added tasks that have not yet been commercialized.
There is still work to be done. There is currently no single framework available to provide reinforcement learning solutions. It is expected that in the next few years, major cloud service providers will provide similar services. Efforts in this area include Microsoft Project Bonsai, Amazon’s SageMaker RL and Google’s SEED RL.
Five, turn on the “top-down” reinforcement learning mode
In the team’s information system, most of the established artificial intelligence infrastructure can be used for reinforcement learning, including technical teams, IT infrastructure, and machine learning related patented technologies and methodology. However, considering the early maturity of reinforcement learning in the group, customized application requirements, and application ability requirements, reinforcement learning in the team should be promoted in a “top-down” model, through the leadership strategy It is the basis for the development of intensive learning.
1. Identify business problems and carry out reinforcement learning experiments
First determine the process of reinforcement learning, release business and optimize performance through reinforcement learning (refer to Appendix 2). Ideally, choosing a well-formed AI learning environment can accelerate the training process of artificial intelligence applications.
Based on McKinsey’s experience, before implementing reinforcement learning, each team should ask itself internally: “What are the business challenges that we cannot solve with traditional modeling methods?” This is to determine whether the established process is suitable for One of the best ways to strengthen learning.
Many artificial intelligence projects that are being promoted have too many dynamic factors in the environment and low model consistency, resulting in a lot of data that is not specific, and only estimates and approximate data can be used. This makes the implementation of artificial intelligence very slow, and a large number of projects cannot be commercialized.
During the AI application process of the New Zealand Emirates, the test cycle of new ships is often disrupted by the schedule of the sailors involved in the test, and the cost of these sailors to lay down their work and participate in the test is also very high.
In addition, reinforcement learning using deep neural networks is usually complex and difficult to explain. Therefore, in some industries that require data and model transparency, reinforcement learning cannot cooperate with regulators or operators to implement strict supervision of enterprises. However, in relatively loose fields, companies are not able to apply reinforcement learning in the process of applying reinforcement learning.Too much energy needs to be wasted on studying the operating mechanism of the reinforcement learning system.
2, pre-calculate cost factors
An overview of accelerating AI learning efficiency. The reward mechanism is usually the most costly part of the development process. This can be said to be the “art of science”.
Project managers and data scientists need to continuously improve the reward hacking incentive mechanism to figure out how to calibrate rewards correctly so that AI can make complex decisions in the best way.
Teams can establish basic principles for AI and use them to estimate potential costs. Leaders should understand and discuss potential cost drivers with the team in advance to ensure that the process is smoother and the team can focus on future work.
3. Make your emulator never out of date
Many teams focused on manufacturing and operations have begun to use analog or digital twins to tune asset performance and utilization. However, in order to achieve reinforcement learning, the simulator and model need to be continuously upgraded during the application process.
Many traditional simulators are designed to run on a small scale. Under this premise, only one simulator can be run at a time, and manual operation is required. And if the simulator is upgraded to a platform and migrated to the cloud environment, thousands of simulators can be run in parallel. However, this model requires the development of API interfaces between AI and cloud environments so that AI agents can interact with them.
In most cases, whether you are building or rebuilding a digital simulator, you should consider issues beyond existing use cases and make design choices to provide application flexibility for new technologies and use cases that are unknown in the future.
With the deepening development of reinforcement learning technology, enterprises need faster deployment models, and deployment in a flexible and efficient cloud model can make enterprises one step faster in the process of implementing new solutions.
4. Pay more attention to human employees
In the process of reinforcement learning applications, its greatest value lies in the use of technology to empower humans, not to replace them. Only by realizing this can the application of reinforcement learning be considered a real success.
Any AI relies on experts in the field of its application and their expertise. The AI technical team needs these experts to provide data and technical support for the AI model, so as to ensure the accuracy of AI predictions and maximize the value of AI recommendations . Successfully integrate AI into the workflow to achieve optimized management and improve efficiency.
In the application of reinforcement learning, industry experts need to guide the construction of AI models throughout the process, build and test the logic of reinforcement learning together with data scientists, and monitor the performance of AI for a long time after deployment.
In addition, the team applying reinforcement learning should also carefully consider whether it is necessary to set up a human employee who makes the final decision in the logic loop of AI to help andGuide AI to make the final decision.
The AI agents of the Emirates Team of New Zealand recommend the optimal design from the thousands of projects they have tested, and then the human sailor will personally take the helm, combined with the digital simulator to test the performance, and perform the performance ranking of the final design results, and finally Design the hydrofoil sailboat that performs best on the field.
5. Identify and manage potential risks of AI applications
When deciding where to use intensive learning, the most important thing is to recognize employees and society’s concerns about the interpretability and use of the autonomous learning system.
In this regard, McKinsey has done a lot of research on the unintended consequences of AI. When a team does not fully understand the possible risks of AI applications, or does not clarify the role of the team leader in building an artificial intelligence system, it is difficult for the construction and promotion of artificial intelligence to achieve the expected goals, and there may even be a lot of potential management. risk.
With the development of intensive learning, leaders need to strengthen their own learning, focusing on the ethical issues of AI, positioning in the enterprise, and how to effectively manage AI, etc., to increase knowledge reserves, so as to “top down “To guide companies to make correct judgments on AI technology.
Reference link:
https://www.mckinsey.com/business-functions/mckinsey-analytics/our-insights/its-time-for-businesses-to-chart-a-course-for-reinforcement-learning?cid=other -eml-alt-mip-mck&hdpid=51dd8d4c-5701-4ea1-bb66-4bf0dda1c8a6&hctky=12582690&hlkid=a2ccd2a6bd764780869c83c50ac7376e