How does speech recognition technology come along?
Editor’s note: This article is from WeChat public account “AI Technology Base Camp” (ID: rgznai100), authors Chen Xiaoliang, Feng Dahang, Li Zhiyong.
[Introduction] Since the birth of speech recognition since half a century ago, it has been in a tepid state. Until the deep development of deep learning technology in 2009, the accuracy of speech recognition has been greatly improved, although it has not been possible. Unrestricted areas, unlimited population applications, but also provide a convenient and efficient way of communication in most scenarios.
This article will review the history and current status of speech recognition from both technical and industrial perspectives, and analyze some future trends. I hope to help more young technicians understand the voice industry and generate interest in this industry.
Speech recognition, commonly referred to as automatic speech recognition, is Automatic Speech Recognition, abbreviated as ASR, which is mainly used to convert vocabulary content in human speech into computer-readable input, which is generally understandable text. The content may also be a binary code or a sequence of characters. However, the speech recognition that we generally understand is actually a process of narrow speech-to-text, referred to as Speech To Text (STT), which is more suitable for text to speech (TTS).
Speech recognition is a cutting-edge technology that integrates multidisciplinary knowledge. It covers basic and frontier disciplines such as mathematics and statistics, acoustics and linguistics, computer and artificial intelligence, and is a natural interaction technique. The key link. However, since the birth of speech recognition for more than half a century, it has not been widely recognized in the practical application process. On the one hand, it is related to the technical defects of speech recognition, and its recognition accuracy and speed are not up to the requirements of practical applications; On the one hand, it is related to the industry’s high expectations for speech recognition. In fact, speech recognition and keyboard, mouse or touch screen should be a fusion relationship, not a substitute relationship.
Deep learning technology has made great strides since its rise in 2009. The accuracy and speed of speech recognition depends on the actual application environment, but the speech recognition rate in quiet environment, standard accent, and common vocabulary scenes has exceeded 95%, which means that it has the same language recognition ability as human beings, and this is also speech recognition. The current development of technology is hot.
With the development of technology, speech recognition in accent, dialect, noise and other scenes has now reached a usable state, especially in far-field language.Tone recognition has become one of the most successful technologies in the global consumer electronics field with the rise of smart speakers. Since voice interaction provides a more natural, convenient, and efficient form of communication, voice is bound to become one of the most important human-computer interaction interfaces in the future.
Of course, there are still many shortcomings in the current technology, such as speech recognition in scenes such as strong noise, super far field, strong interference, multilingual, and large vocabulary. In addition, multi-person speech recognition and offline Speech recognition is also a problem that needs to be addressed at present. Although speech recognition cannot be applied to unlimited areas and unlimited people, at least we have seen some hopes from application practice.
This article will review the history and current status of speech recognition from both technical and industrial perspectives, and analyze some future trends, hoping to help more young technicians understand the voice industry and generate interest in this. industry.
Technical history of speech recognition
Modern speech recognition dates back to 1952, when Davis et al. developed the world’s first experimental system that recognizes 10 English-speaking pronunciations, and officially opened the process of speech recognition. Speech recognition has been developed for more than 70 years, but it can be roughly divided into three stages from the technical direction.
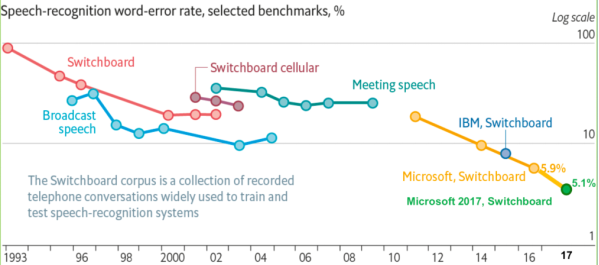
The following picture shows the progress of speech recognition rate on Switchboard from 1993 to 2017. It can also be seen from 1993 to 2009 that speech recognition has been in the GMM-HMM era, and the speech recognition rate has been slow. In particular, from 2000 to 2009, the speech recognition rate was basically stagnant; in 2009, with the deep learning technology, especially the rise of DNN, the speech recognition framework became DNN-HMM, and speech recognition entered the DNN era, and the speech recognition accuracy rate was obtained. Significant improvement; after 2015, due to the rise of “end-to-end” technology, speech recognition has entered the era of blooming, the voice industry is training deeper and more complex networks, and the end-to-end technology is used to further enhance the performance of speech recognition. Until 2017, Microsoft reached a word error rate of 5.1% on Swichboard, which made the accuracy of speech recognition surpass humanity for the first time. Of course, this is the experimental result under certain limited conditions, and it is not universally representative.
GMM-HMM era
In the 1970s, speech recognition focused on small vocabulary and isolated word recognition.The method used is mainly a simple template matching method, that is, the feature construction parameter template of the speech signal is first extracted, and then the test speech and the reference template parameters are compared and matched one by one, and the words corresponding to the nearest sample are marked as The pronunciation of the speech signal. This method is effective for solving isolated word recognition, but it can’t do anything for large vocabulary and non-specific continuous speech recognition. Therefore, after entering the 1980s, the research ideas have undergone major changes, starting from the traditional technical idea of template matching and turning to the technical idea based on statistical model (HMM).
The theoretical basis of HMM was established by Baum et al. around 1970, and then applied to speech recognition by Caker’s Baker and IBM’s Jelinek et al. The HMM model assumes that a phoneme has 3 to 5 states, the pronunciation of the same state is relatively stable, and different states can jump according to a certain probability; the feature distribution of a state can be described by a probabilistic model, and the most widely used model is GMM. Therefore, in the GMM-HMM framework, the HMM describes the short-term stationary dynamics of speech, and the GMM is used to describe the pronunciation features inside each state of the HMM.
Based on the GMM-HMM framework, the researchers propose various improvements, such as dynamic Bayesian methods combined with context information, discriminative training methods, adaptive training methods, and HMM/NN hybrid model methods. These methods have had a profound impact on speech recognition research and are ready for the generation of next-generation speech recognition technology. Since the discriminative training criteria and model adaptive methods of the speech recognition acoustic model in the 1990s have been proposed, the development of speech recognition has been slow for a long period of time, and the line of speech recognition error rate has not decreased significantly.
DNN-HMM era
In 2006, Hinton proposed the Deep Trust Network (DBN), which led to the recovery of deep neural network (DNN) research. In 2009, Hinton applied DNN to the acoustic modeling of speech and achieved the best results at TIMIT. At the end of 2011, Yu Dong and Deng Li of Microsoft Research Institute applied DNN technology to large vocabulary continuous speech recognition tasks, which greatly reduced the speech recognition error rate. From then on, speech recognition entered the DNN-HMM era.
DNN-HMM mainly uses the DNN model instead of the original GMM model to model each state. The advantage of DNN is that it no longer needs to make assumptions about the distribution of voice data, and the adjacent speech frames are spliced and included. The temporal structure information of the speech makes the classification probability of the state significantly improved, and the DNN also has powerful environmental learning ability, which can improve the robustness against noise and accent.
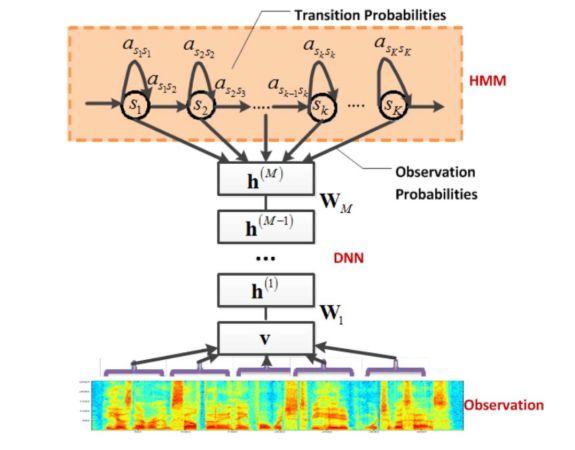
In a nutshell, DNN is giving input The state probability corresponding to a string of features. Since the speech signal is continuous, not only are there distinct boundaries between individual phonemes, syllables, and words, but each unit of pronunciation is also affected by the context. Although stitching can increase context information, it is not enough for voice. The emergence of recurrent neural networks (RNN) can remember more historical information, and is more conducive to modeling the context information of speech signals.
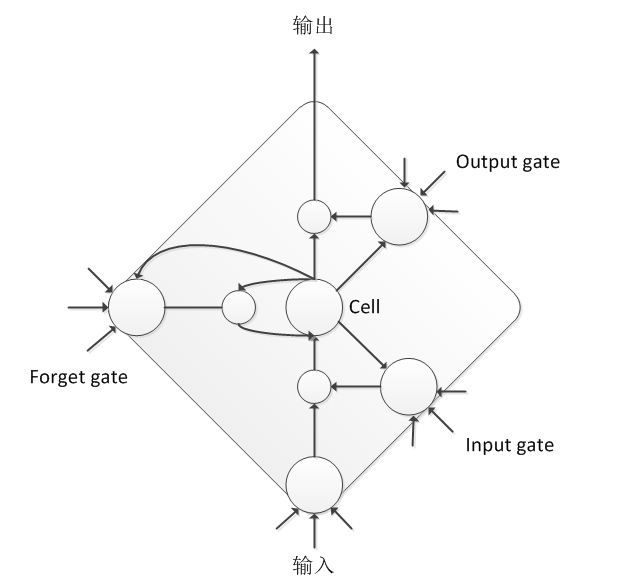
Since the simple RNN has gradient explosion and gradient dissipation problems, it is difficult to train and cannot be directly applied to speech signal modeling. Therefore, scholars have further explored and developed many RNN structures suitable for speech modeling, the most famous of which is LSTM. LSTM provides better control of the flow and transmission of information through input gates, output gates, and forgetting gates, with long and short-term memory capabilities. Although the computational complexity of LSTM is higher than that of DNN, its overall performance is steadily increasing by about 20% compared to DNN.
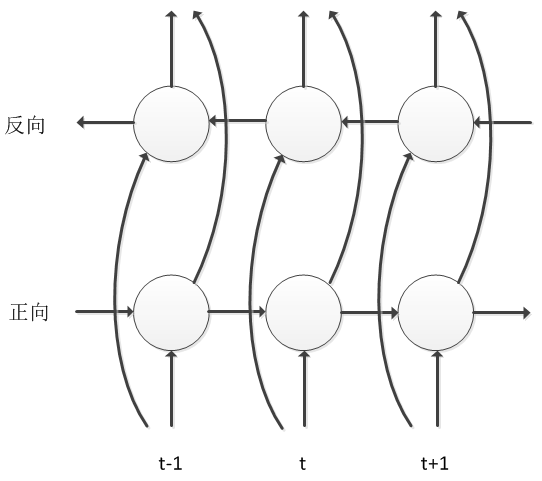
BLSTM is a further improvement based on LSTM Consider not only the influence of the historical information of the speech signal on the current frame, but also the influence of future information on the current frame. Therefore, there are two forward and reverse information transmission processes along the time axis in the network, so that the model can be more fully Considering the influence of the context on the current speech frame, the accuracy of the speech state classification can be greatly improved. The cost of BLSTM considering future information is that it needs to be updated at the sentence level. The convergence speed of model training is slower, and it also brings the delay of decoding. For these problems, the engineering has been optimized and improved, even if there are still many big ones. The company uses the model structure.
The mainstream model in image recognition is CNN, and The time-frequency diagram of the speech signal can also be regarded as an image, so CNN is also introduced into speech recognition. In order to improve the speech recognition rate, it is necessary to overcome the diversity of speech signals, including the speaker itself, the environment in which the speaker is located, the acquisition device, etc. These diversity can be equivalent to various filters and languages.Convolution of the tone signal. CNN is equivalent to designing a series of filters with local attention characteristics, and learning the parameters of the filter through training to extract the invariant parts from the diversity of speech signals. CNN can also be regarded as A process of continuously extracting features from a speech signal. Compared with the traditional DNN model, CNN has fewer parameters in the same performance.
In summary, for modeling capabilities, DNN is suitable for feature mapping to independent space, LSTM has long and short memory, and CNN is good at reducing the diversity of speech signals, so a good speech recognition system is the network. combination.
End-to-end era
The end-to-end method of speech recognition is mainly that the cost function has changed, but the model structure of the neural network has not changed much. In general, end-to-end technology solves the problem that the length of the input sequence is much larger than the length of the output sequence. End-to-end technologies fall into two main categories: one is the CTC method and the other is the Sequence-to-Sequence method. Traditional Speech Recognition The acoustic model in the DNN-HMM architecture, each frame input corresponds to a tag category, and the tags require iterative iterations to ensure more accurate alignment.
A sequence of acoustic models using CTC as a loss function does not require prior alignment of the data. Only one input sequence and one output sequence are required for training. The CTC is concerned with whether the sequence of the predicted output is similar to the actual sequence, regardless of whether each result in the predicted output sequence is exactly aligned with the input sequence at the point in time. The CTC modeling unit is a phoneme or word, so it introduces Blank. For a piece of speech, the CTC finally outputs a sequence of spikes, the position of the peak corresponds to the Label of the modeling unit, and the other positions are Blank.
The
Sequence-to-Sequence method was originally used primarily in the field of machine translation. In 2017, Google applied it to the field of speech recognition, which achieved very good results, reducing the word error rate to 5.6%. As shown in the following figure, Google proposes that the framework of the new system consists of three parts: the Encoder encoder component, which is similar to the standard acoustic model, which inputs the time-frequency characteristics of the speech signal; it is mapped to advanced features through a series of neural networks. The henc is then passed to the Attention component, which uses the henc feature to learn the alignment between the input x and the predicted subunit, which can be a phoneme or a word. Finally, the output of the attention module is passed to Decoder, which generates a probability distribution of a series of hypothetical words, similar to a traditional language model.
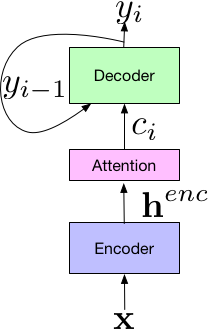
A breakthrough in end-to-end technology, no longer need HMM to describe changes in the internal state of the phoneme, but to recognize the speech All modules are unified into a neural network model, which makes speech recognition develop in a simpler, more efficient, and more accurate direction.
Technical Status of Speech Recognition
At present, the mainstream speech recognition framework is composed of three parts: acoustic model, language model and decoder, and some frameworks also include front-end processing and post-processing. With the rise of various deep neural networks and end-to-end technologies, acoustic models are very popular in recent years, and the industry has released their own new acoustic model structure to refresh the identification records of various databases. Due to the complexity of Chinese speech recognition, domestic research on acoustic models is progressing relatively faster. The mainstream direction is deeper and more complex neural network technology fusion end-to-end technology.
In 2018, the University of Science and Technology launched a deep full-sequence convolutional neural network (DFCNN). DFCNN used a large number of convolutions to directly model the entire sentence speech signal, mainly borrowing the network configuration of image recognition, each convolution. The layer uses a small convolution kernel and adds a pooling layer after multiple convolutional layers. By accumulating a very large number of convolutional pooling layer pairs, more historical information can be seen.
In 2018, Ali proposed LFR-DFSMN (Lower Frame Rate-Deep Feedforward Sequential Memory Networks). The model combines the low frame rate algorithm with the DFSMN algorithm. The speech recognition error rate is reduced by 20% compared to the previous generation technology, and the decoding speed is increased by 3 times. FSMN can effectively model the long-term correlation of speech by adding some learnable memory modules in the hidden layer of FNN. DFSMN can avoid the deep gradient of the deep network by jumping, and can train a deeper network structure.
In 2019, Baidu proposed a streamed multi-level truncated attention model, SMLTA, which introduced attention mechanisms based on LSTM and CTC to obtain larger and more hierarchical context information. The streaming representation can directly perform a small segment of a small segment of incremental decoding of speech; multi-level representation of a stacked multi-layered attention model; truncation means using the CCT model’s spike information to cut the speech into a small segment, note Force models and decoding can be expanded on these small segments. In terms of online speech recognition rate, this model is 15% better than Baidu’s previous generation Deep Peak2 model.
Open source speech recognition Kaldi isThe cornerstone of the industry’s speech recognition framework. Kaliel’s author Daniel Povey has always been praising the Chain model. The model is a CTC-like technology. The modeling unit is coarser and grainier than the traditional state. There are only two states, one is the CD Phone and the other is the blank of the CD Phone. The training method is Lattice-Free MMI training. The model structure can be decoded in a low frame rate, and the decoding frame rate is one-third of that of the traditional neural network acoustic model, and the accuracy rate is significantly improved compared to the conventional model.
The far-field speech recognition technology mainly solves the problem of human-machine task dialogue and service within the comfortable distance under real scenes, and is a technology that has begun to emerge after 2015. Because far-field speech recognition solves the problem of recognition in complex environments, it has been widely used in practical scenes such as smart home, smart car, intelligent conference, and intelligent security. At present, the technical framework of far-field speech recognition in China is mainly front-end signal processing and back-end speech recognition. The front-end uses the microphone array for signal processing such as de-reverberation and beamforming to make the speech clearer and then sent to the speech recognition engine at the back end. Identify.
The other two technical parts of speech recognition: the language model and the decoder, there is not much technical change at present. The mainstream of the language model is still based on the traditional N-Gram method. Although there are also language model researches of neural networks, it is mainly used for post-processing error correction in practice. The core indicator of the decoder is speed. Most of the industry is based on static decoding. The acoustic model and the language model are constructed into a WFST network. The network contains all possible paths, and decoding is the process of searching in this space. Because the theory is relatively mature, and more is the problem of engineering optimization, so academic or industry is currently less concerned.
Technical trends in speech recognition
Voice recognition mainly tends to develop in the direction of far-field and fusion. However, there are still many difficulties in far-field reliability. There are still many breakthroughs, such as multi-round interaction and multi-person noise. Urgent vocal separation and other technologies. New technologies should completely solve these problems, making machine hearing far beyond human perception. This can’t just be an advancement of the algorithm, it requires a common technology upgrade of the entire industry chain, including more advanced sensors and more powerful chips.
From the far field speech recognition technology, there are still many challenges, including:
(1) Echo cancellation technology. Due to the existence of nonlinear distortion of the horn, it is difficult to eliminate the echo by simply relying on the signal processing method, which also hinders the promotion of the voice interactive system. The existing echo learning techniques based on deep learning do not consider the phase information and directly seek the phase information. Is the gain in each frequency band, can use nonlinear learning to nonlinear distortion