Camera vs. Lidar
Editor’s note: This article is from WeChat public account “AI front line” (ID : ai-front) , author: Nathan Hayflick, Translator: Nuka-cola. (Original title: Face Musk! “The unmanned car relies on LiDAR to be doomed to fail” is measured as nonsense)
AI Frontline Guide: On Tesla’s 2019 Driverless Day, Elon Musk issued an important “indication” to LiDAR (Light Detection and Ranging) technology “, Forecast: “Anyone who relies on LiDAR technology will be doomed to fail”. Although laser radar has been recognized by many driverless car manufacturers in the past decade, Musk declared:
Tesla only needs an existing camera and sensor kit installed on the vehicle to achieve driverless functionality. In his view, the road to driverlessness is not about adding more sensors, but by introducing a lot of training data from the real world. It is clear that Tesla’s fleet has the ability to collect huge amounts of data and combine it with industry-leading computer vision technology.
Muske’s forecast highlights one of the more serious problems in the development of driverless cars:
Whether it’s the choice of a driver-less solution to achieve driverlessness like a human driver, or a LiDAR-like sensor to compensate for some of the limitations of computer vision technology. The current debate is not over yet. After all, neither of these methods has achieved large-scale unmanned vehicle deployment, and the publicly available technical data available for comparison is very limited. In the face of this challenge, the author of this article, Nathan Hayflick, hopes to use his tools to test the two implementation concepts with a set of data-marking products built by Scale for unmanned developers.
The devil is in the data
First talk about background information: Perceptual systems need to learn not only to understand highway conditions on their own, but also to use a large training data set built from human-verified data. This method is classified as a “supervised learning” system. Specific training data includes partial output of the car sensor (egThe video image of the road ahead or the 3D LiDAR point cloud of the vehicle’s surroundings. These outputs are sent to human operators who are responsible for labeling the location and type of each object. Unmanned vehicles need to learn to “observe”.
Because marker data is used as the primary perceptual input in car training, we often judge the quality of the training data to determine whether the sensory system of the driverless vehicle works well. To build a sensor-aware system with extremely high accuracy and drive the car’s body, it’s not enough to have a lot of data—we must also be able to annotate the data with great accuracy, otherwise the performance of the sensing system will occur. Significantly retrogressive.
Our experiment is also unfolding! Scale has a complete set of toolchains that can generate datasets from any combination of sensors, and we recently provided annotations for nuScenes via Aptiv. nuScenes is a set of 3D video created by an in-vehicle camera with LiDAR in conjunction with Aptiv. Can we compare the training data generated by each system to compare the performance of a camera-based system with a LiDAR-based system?
To answer this question, we extracted a series of driving scenarios from the 3D dataset, but only used 2D video images, and then re-marked them into a set of 2D datasets that did not use LiDAR-aware systems. After that, we project these 2D annotations [1] to the original 3D data and compare the objects one by one to see if there is a loss of accuracy.
Dairdown: Camera Pair LiDAR
After the two sets of datasets were tagged and prepared, we compared the results and found a series of significant differences. Many of the comments that appear to be perfectly reasonable when superimposed on the video can produce significant misrepresentations when extended to the 3D environment. The following picture is an example – if you only look at the 2D image on the left, at first glance the two sets of data sets seem to be accurate. But in the pure 3D scene on the right, we will find that the annotations of the pure video dataset are too long and lack the environmental observations on the entire side.

Left: Using the combination of LiDAR plus video, the same vehicle has better annotations to capture the width and length of the vehicle more accurately; right: Top view generated by LiDAR annotations
Why does the accuracy in 2D scenes worsen when extended to 3D? Did you make any mistakes for the operator who outlined the bounding frame of the vehicle? This is not the case—in other words, using planar images to infer accurate 3D quantization results is inherently challenging. This is equivalent to drawing a standard 3D cuboid around an object with irregular appearance (the car has various shapes and different accessories, and the driverless car may encounter multiple vehicles, pedestrians and wildlife while driving). This requires the system to clearly understand the location of all boundary points.
In the 2D perspective, we can at least ensure that these boundary points are either integrated into the object itself or obscured by the object itself. Taking the minivan in the picture as an example, the left and right edges of the vehicle are easy to find, but because of the similar background tones in the scene, it is difficult to find a clear visual element to accurately map the left rear corner of the vehicle. To make matters worse, the back of the pickup truck has a sloping, streamlined design. Although the caller can try to fill in these blanks, but ultimately underestimate the width of the object, causing the cuboid to be unable to align when rotated, and finally the observation points on the left side of the vehicle in the 3D view are cut off.
If we look closely at the leftmost edge, the main result of seeing the 2D annotation also underestimates the height of the object because it cannot determine where the hood of the small truck will extend to which location. This situation comes from a basic mathematical feature—depth information naturally “shrinks” in 2D images. When the object is close to the horizon, moving only a few pixels at the far edge can significantly increase the perceived cuboid depth.

When 2D is projected to 3D, LiDAR plus camera annotations (white) have only a few pixels of error, which is magnified by a pure camera annotation (orange) to a more serious error
In order to solve this problem, we can hard-code the vehicle size into the system (enter the design size of all cars). But very quickly, there will be a lot of exceptions (including vehicles loaded with goods) or missing standard size object categories (egBuilding area). This prompted us to take advantage of machine learning-based solutions to extract size from objects – but this approach also brings new challenges, which we will explain later.
According to our experience, the best way to solve this type of problem is to refer to high-resolution 3D data – this is where LiDAR’s expertise lies. Looking at the LiDAR point cloud, we realize that it can solve almost all the problems, because the captured points track the left and right boundaries of the vehicle, ensuring that we use these results to set the cuboid edges. In addition, the depth distortion problem mentioned earlier does not exist in the LiDAR scenario.
The second game: driving at night
Considering the practical scenarios that driverless cars need to face, the case in the first round of confrontation seems too simple. Now, we have to introduce a bit of real-world complexity into our tests and make the difference between the two sets of data more extreme. Here, we see that the system captures a car that is driving at night, which suddenly changes in front of the driverless vehicle.
The visibility on the site is very poor, and the right traffic sign is blocked, causing visual interference to the headlights of the vehicle. In this case, 3D data can provide a more accurate steering and depth conclusion for the vehicle – this is because the LiDAR sensor with a higher mounting point can help the vehicle to cross the traffic sign for viewing and then measure the target vehicle. Edge and driving angle.

It can be seen that behind the lamppost and shrub on the right side of the picture, there is indeed a driver riding an electric car. The rider is dressed in black clothing, coupled with a very low-light image of the grain, making it difficult for us to judge whether it is a shadow or a real object. The object is completely ignored in the pure video training data, so the LiDAR annotation succeeds in recording the captured result.

Left: The electric car and rider seen by the camera, most of the objects are obscured by the low shrubs; Right: the top view in LiDAR, the object points indicate the presence of electric cars and riders
Unrecognized such objects poses a significant risk to unmanned vehicles. Since video images are too blurry, cars without LiDAR have only two choices: ignore them directly; or illusion when visibility is poor or driving style is too cautious, and moving shadows as another rider (causing car emergency) To avoid collisions with imaginary targets). These two practices are clearly not safe for unmanned vehicles driving on public roads.
Perception and Prediction
It can be seen that predicting 3D markup results with pure 2D sensor data presents a number of challenges, but are these problems widespread? We performed a statistical analysis of all the cuboid rotation errors in the data set and found an average correlation of 0.19 radians (10.8 degrees) between the pure video annotation and the LiDAR-verified corresponding results. After further analysis of the data, we found that the average error of the night annotation is 0.22 radians, which is much higher than the error of 0.16 radians in the daytime scene, and the error increases as the distance between the target and the camera increases, and the accuracy naturally decreases synchronously.
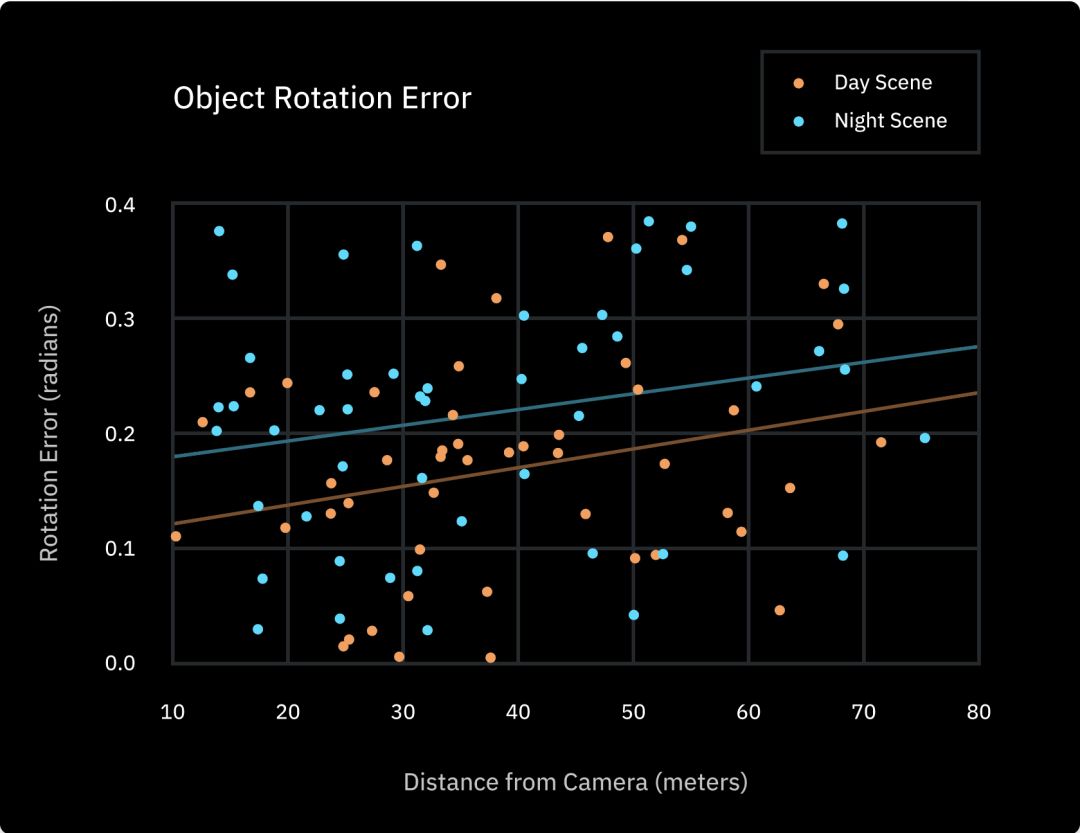
To further quantify this pattern, we will annotate all 2D and 3D results. The IOU score was graded using the standard quality indicator of the object detection task. (The full name of IOUIntersection Over Union, a common metric in object detection tasks, measures the “difference” between two shapes, taking into account errors in position, shape, and size. The average score for the overall data set is 32.1%, but in general, it is usually considered “correct” to get more than 90% of the IOU score.
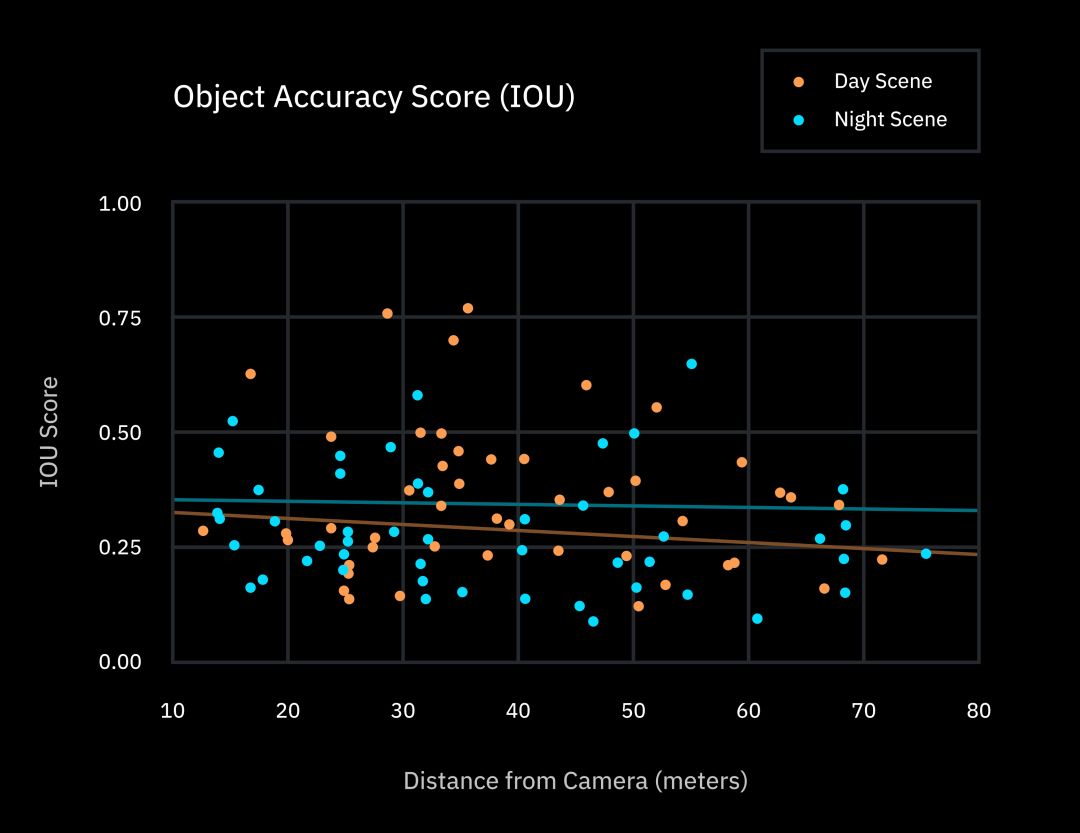
Relevant insights
So, what is the significance of such a conclusion? Simply put, this emphasizes that the human brain takes a completely different perspective on the world of perception than the software of driverless cars. When it comes to physical motion planning, we don’t need to perform environmental-based mathematical operations in our minds, but we can quickly determine potential risks and brake in time.
If your perception system is not strong enough or accurate enough, the predictive power will be greatly reduced.
In contrast, driverless cars must perform this type of calculation and are primarily implemented through an initial design. Using neural network prediction systems (often requiring a lot of debugging and high degree of confusion) it is very dangerous to directly control a driverless car (end-to-end learning method); instead, we should take the driverless car The “brain” is split into smaller systems, such as first building a perception system, then predicting, planning, and ultimately operating the operating system.
Perception is the foundation, because the execution of late steps such as prediction and planning will depend on the perception system being able to correctly predict the location of the object and how it will interact with the driverless car. If your perception system is not strong enough or accurate enough, the predictive power will be greatly reduced.
In a relatively simple environment such as a highway, these may not be as important. After all, the range of motion of the vehicle is small. However, in the case of full-scale unmanned driving, there are still a large number of safe control scenarios that need to be predicted in advance. (For example, to determine when it is safe to move to the left, or to bypass a stationary car).
In addition, Almost all driverless stacks take a top-down perspective for route planning, so once the width of the object car is misjudged (as our first example), it may lead to the system. Mistakes predict the action or distance of the vehicle ahead.. Although many opponents of the laser radar believe that “we can drive normally without rotating the LiDAR sensor, so good GodIt should be done via the network. But there is no doubt that the software architecture of the driverless car should provide better predictive power to achieve better perceptual accuracy than humans.
At present, the main challenge for non-LiDAR system developers is to find ways to get the ideal annotation accuracy from 2D data. Because of this, Tesla will try to explore how to predict the size and location of objects in a series of systematic experimental studies demonstrated during its Unmanned Day activities. One of the most popular methods recently is to create a set of point clouds using a stereo camera (similar to humans using the parallax of both eyes to determine the distance).
But so far, there is no evidence that this is an ideal choice because it requires us to measure object distance using a very high resolution camera. Another method in the demonstration is to use an additional machine learning layer to understand the size and depth of the object. Ultimately, this means that the safety system on the vehicle will be more dependent on the neural network and will have more serious unpredictability and terrible consequences in extreme situations.
The LiDAR-based system is able to measure distance and size directly, so that the vehicle’s sensing system can cope with the erroneous results given by the neural network in a more comfortable way. The Tesla side demonstrated an example of using a neural network system for topographical depth prediction, but even in relatively simple scenes (daytime, highway), the predicted vehicle size also has significant size and angular distortion.

Tesla’s vehicle bounding box based on camera data. When viewed from a top view angle, the vehicle in the left lane shows a deep distortion when it is far from the camera, while the vehicle in the right lane has a problem of inaccuracy in width and rotation. Source: Tesla Driverless Day, 2019.
To summarize the comments
Although 2D annotations may seem accurate, they often hide deeper inaccuracies. Wrong data will control the credibility of the machine learning model, and the output of these models will further affect the vehicle’s forecasting and planning software. If you can’t make a breakthrough in computer vision research, such driving systems can be difficult to achieve true autonomy – after all, vehicles must make thousands of predictions per mile of driving, and there is no loss.
-
However, 2D annotations can still be an important part of an overall sensor system or for handling simple tasks such as object sorting while maintaining the lane or highway driving.
-
Having multiple sensor modes always makes you feel more at ease. One of the main advantages of combining a camera with lidar data is that when a sensor type does not recognize the road condition (for example, if a car is blocked by a traffic sign in front, or if the camera just under the bridge is temporarily unable to adjust the exposure time) Imaging), we can also rely on another sensor to fill in the missing information.
-
From a broader perspective, our findings are also expected to bring a virtuous cycle to machine learning development: using more powerful sensors to generate more accurate training data, which means our perception model Will perform better and in turn reduce our dependence on any sensor. But there is another bad possibility here: even if there is theoretically the possibility of not using LiDAR to build a safe drone system, it is necessarily more difficult to use the camera alone to obtain good training data. Therefore, unless the machine learning technology undergoes subversive changes, a large amount of mediocre training data will only allow us to stay in place for a long time. Without high-quality data, developers will face a tough battle—how to train their perception systems to the level of accuracy that truly meets the requirements of unmanned safety.
Remarks
-
We use the internal data of the Nuscene camera to calibrate the 2D box to a pseudo 3D form, and then use the external data to scale the box to 3D. At a known reference point in the environment (in our example, the point closest to the ground), two comparable measurement objects are obtained.
Original link:
https://scale.com/blog/is-elon-wrong-about-lidar Are you “watching”?