png” o:title=”table
Description is automatically generated”/> NVIDIA H100 defeated NVIDIA A100 and took over the world’s largest AI acceleration chip (H100 integrates 80 billion transistors, 26 billion more than the previous generation A100; CUDA cores soared to 16896, It is nearly 2.5 times that of A100), which may be the legendary “only oneself can conquer oneself”.
NVIDIA H100 defeated NVIDIA A100 and took over the world’s largest AI acceleration chip (H100 integrates 80 billion transistors, 26 billion more than the previous generation A100; CUDA cores soared to 16896, It is nearly 2.5 times that of A100), which may be the legendary “only oneself can conquer oneself”.
Coincidentally, “oneself conquer oneself” also has the Hopper architecture. NVIDIA announced that Hopper’s next-generation accelerated computing platform will replace the Ampere architecture launched two years ago. Ampere is NVIDIA’s most successful GPU architecture to date.
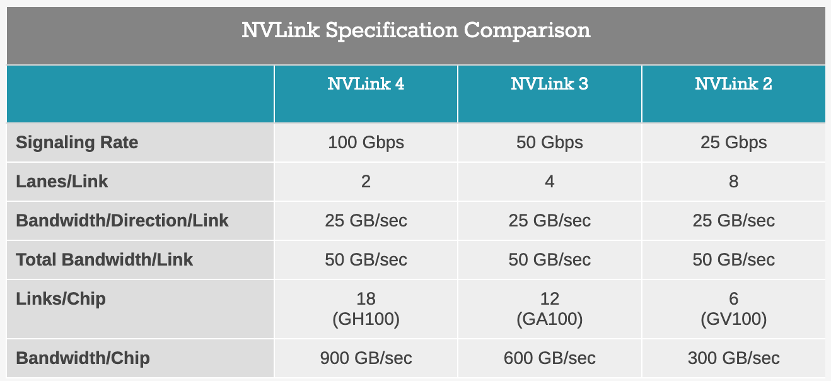
H100 is NVIDIA’s first based on Hopper architecture GPU. According to Huang Renxun, H100 adopts TSMC’s latest 4nm process, not 5nm which has been circulating for a long time. At the same time, H100 is equipped with the fourth-generation NVLink high-speed GPU interconnection technology, which can connect up to 256 H100 GPUs and expand the bandwidth speed to 900GB/s.
 At the same time, H100’s mathematical computing capability has also been improved, and Hopper has introduced a new instruction set called DPX, It can accelerate dynamic programming. Compared with the CPU and the previous generation GPU, the speed of dynamic programming algorithm optimization problems such as computing path optimization and genomics is improved by 40 times and 7 times respectively.
At the same time, H100’s mathematical computing capability has also been improved, and Hopper has introduced a new instruction set called DPX, It can accelerate dynamic programming. Compared with the CPU and the previous generation GPU, the speed of dynamic programming algorithm optimization problems such as computing path optimization and genomics is improved by 40 times and 7 times respectively.
“20 H100s can carry global Internet traffic”, Huang Renxun said at the GTC conference, “Hopper H100 is the biggest performance leap ever – its large-scale training performance is 9 times that of A100 for large-scale language model inference The throughput is 30 times that of the A100.” According to reports, the H100 will be available in the third quarter of this year.
Currently, the H100 has two versions: one It is an SXM with an unprecedented thermal power consumption of 700W (called NVIDIA’s “nuclear bomb factory” in the professional field), which is used for high-performance servers; the other is suitable for more mainstream servers PCIe, and its power consumption is more than the 300W of the previous generation A100. 50W.
The latest DGX H100 computing system based on H100 is commonly equipped with 8 GPUs. However, the DGX H100 system achieves 32 Petaflop AI performance under FP8 precision, It is 6 times higher than the previous generation DGX A100 system, and the GPU connection speed of 900GB/s is close to 1.5 times that of the previous generation.
At the GTC conference, Huang Renxun also introduced the The Eos supercomputer built on the basis of DGX H100 has created the world’s first AI supercomputing performance (its 18.4 Exaflops AI computing performance is 4 times faster than Japan’s “Fugaku” supercomputer). Eos is equipped with 576 DGXs The H100 system uses 4608 pieces of H100. In traditional scientific computing, the computing power can reach 275 Petaflops, and the first Fuyue is 442 Petaflops.
H100’s new generation of Hopper architecture is based on “First Lady of Computer Software Engineering” Grace Hopper named. Grace Hopper is one of the pioneers of computer science and invented the world’s first compiler – the A-0 system. In 1945, Grace Hopper discovered a moths that only cause machine failure, since then “bug” and “debug” (deworming) have become special words in the computer field. 
There are “Hopper” and “Grace”. At the GTC conference, Huang Renxun also introduced the latest progress of the super server chip Grace: Grace Hopper super chip and Grace CPU super chip, the former consists of a Grace CPU and a Hopper The latter consists of two Grace CPUs, interconnected by NVIDIA NVLink-C2C technology, including 144 Arm cores, with a memory bandwidth of up to 1TB/s and a power consumption of 500w.
Huang Renxun also showed a data on the spot – the Grace super chip achieved a simulation performance of 740 points in the SPECrate2017_int_base benchmark test, which is 1.5 times that of the current CPU on the DGX A100 (460 Minute).
What is the “performance monster” for? Jen-Hsun Huang: Creating the World/Metaverse
The Omniverse that NVIDIA has been building in recent years now looks like a “metaverse infrastructure” tool, a digital twin It can also be understood as reproducing the physical world in a virtual space, referred to as “creating the world”.
But this is not an entertainment project, and Jen-Hsun Huang’s vision of the future for the Omniverse is to become an integral part of “action-oriented AI.” What does that mean? Huang Renxun took NASA as an example, “Half a century ago, the Apollo 13 moon landing mission encountered trouble. In order to save the crew, NASA engineers created a crew capsule model on Earth to help solve the problem of astronauts in space. Problems encountered.
Amazon uses Omniverse Enterprise to build a virtual “order fulfillment center” to find the most efficient way, Pepsi uses Metropolis and Omniverse to build a digital twin factory simulation run at low cost Troubleshoot problems, and use simulation data to allow AI agents to “practice driving” in a virtual environment that conforms to the physical laws of the real world” and so on are all the same logic.

Build a digital twin factory in Omniverse
Practicing Kung Fu in Omniverse
“AI is ‘full bloom’ in various fields, including new architectures, new learning strategies, larger and more powerful models, new scientific fields, new applications, new industries etc., and all of these areas are developing,” said Jen-Hsun Huang, “NVIDIA is fully committed to accelerating new breakthroughs in AI and the application of AI and machine learning in every industry.
“We will accelerate the entire stack at data center scale over the next decade, again achieving million-X million times performance leap. “, Jen-Hsun Huang said at the end of his speech, “I can’t wait to see what the next million-fold performance leap will bring. “