Introduced AI noise reduction algorithm, high computational intensity neural network, and double wheat algorithm
文 / 姜菁玲
Edit / Shi Yaqiong
On December 26th, Prospecting Technology held a “black technology conference” to officially announce the matrix of AI speech recognition chip products, and launched a voice recognition solution with AI dual wheat noise reduction function-Voitist Sound Whirlwind 612.
It has been reported many times , the exploration technology was established in March 2017, is a voice The AI chip design company whose image AI chip is the core product provides an integrated solution of software and hardware. The core architecture adopted by the product is SFA (Storage First Architecture), which advocates storage-driven computing.
For the SFA architecture, has been introduced in detail , this is a kind of storage wall for AI chips (AI computing resources are abundant, but the storage and data transfer efficiency is low). The architecture is set up to move data between nodes from the data layer and the computing layer through data routes. The controller knows which data and which operators need to have a certain correlation during the dynamic operation, so as to build a more reasonable network path.
Exploration Technology stated that compared with the “CPU-like architecture”, under the same conditions, SFA architecture data access can be reduced by 10 to 100 times; under 28nm process conditions, the system energy efficiency ratio reaches 4T OPS / W, computing resources Utilization exceeds 80%, and DDR bandwidth occupancy is reduced by 5 times.
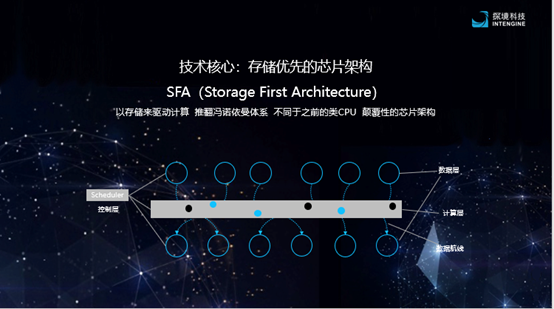
Exploration Technology CEO Lu Yong said that the SFA architecture is universal and can support all current deep learning neural networks. There are no restrictions on neural network parameters and data types. Moreover, it provides a zero-based tool chain that users can use without the need. The user network can be used after retraining, which can reduce the data accuracy reduction caused by algorithm transplantation.
AI noise reduction algorithm + neural network with high computational strength
Sound Whirlwind 611 is the first voice chip solution launched by Discovery. It began mass production in September 2019 and has shipped more than one million units. Voi launched this timeThe tist tone whirlwind 612 is based on the tone whirlwind 611 and has completed the upgrade of the speech recognition algorithm, which is mainly reflected in the AI noise reduction algorithm and the end-to-end algorithm.
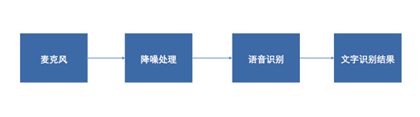
In the process of speech recognition research and development, a complete recognition link can be simplified into four steps: microphone input, noise reduction processing, speech recognition, and recognition result input.
Tongzhi Li, Vice President of Prospecting Technology believes that, taking the smart home scenario as an example, The challenges currently encountered in the field of voice research and development are:
-
Low SNR issues. The signal-to-noise ratio is a measure of the logarithm of the ratio of the intensity of the target sound source to other interference sound sources that need to be identified. Generally, the signal-to-noise ratio below 15dB is called a noise environment. The lower the signal-to-noise ratio, the more difficult it is to recognize. In a real scene, if the intensity of the target sound source is too small, the intensity of noise interference will cause a low signal-to-noise ratio. In addition, because human sound transmission is also affected by distance, the longer the distance, the more the sound intensity is lost. Combining various reasons, the problem of low signal-to-noise ratio is considered the most significant challenge.
-
Non-steady noise effect . In daily life, there may be percussion sounds for cooking, sudden changes in music, etc. These are sudden and unpredictable for noise reduction processing, which has certain difficulties.
-
Multi-sound source problem, Because the principle of traditional signal processing algorithm is to enhance the signal strength in the beam, when the direction of the interference source is close, the traditional processing algorithm cannot solve it .
Aiming at the above pain points, Prospecting Technology has introduced an AI noise reduction algorithm, a high-computational neural network, and a double wheat algorithm. We hope to solve the two problems of noise reduction and identification.
In terms of noise reduction, the AI noise reduction algorithm is used. Based on deep learning, it can process steady-state and non-steady-state noise.
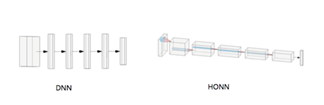
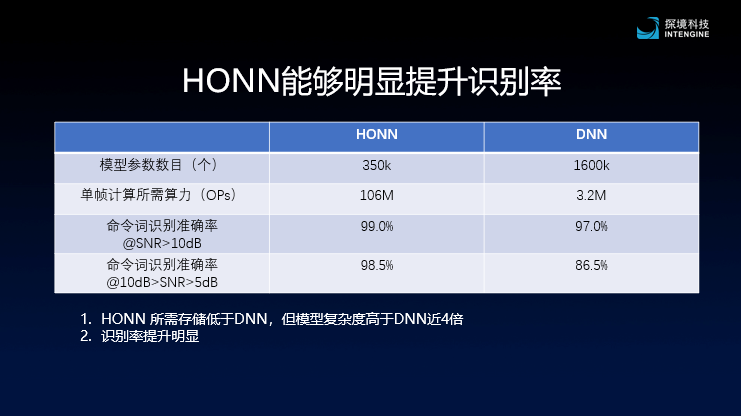
In the aspect of recognition, a neural network model HONN with high computational strength is introduced, which adds more convolution operations and reduces the number of full connections in the traditional DNN / TDNN algorithm.Performance.
Tongzhi Li explained that compared with the traditional DNN / TDNN algorithm, the convolution operation is closer to the brain’s perception system, adding a dimension, and each processing unit becomes three-dimensional.
Exploration technology shows that the amount of parameters required for high-strength neural networks is about one-fifth that of traditional DNN algorithms, and the required computing power is 106M, which is about 30 times higher than DNN3.2M. The effect of this is that a small amount of parameters can save chip storage space and reduce costs, which is equivalent to using less storage space, which brings higher computing power and improves overall performance.
End-to-end AI dual-mic algorithm based on FCSP can improve computing power
In addition, Li Tongzhi also mentioned a situation where the signal-to-noise ratio is 0dB and negative dB, which means that the noise is the same as the signal strength, and even the noise is stronger than the speech signal.
For this situation, the traditional solution is to use the microphone array signal to enhance the algorithm. However, the exploration technology believes that there are four aspects of this algorithm:
-
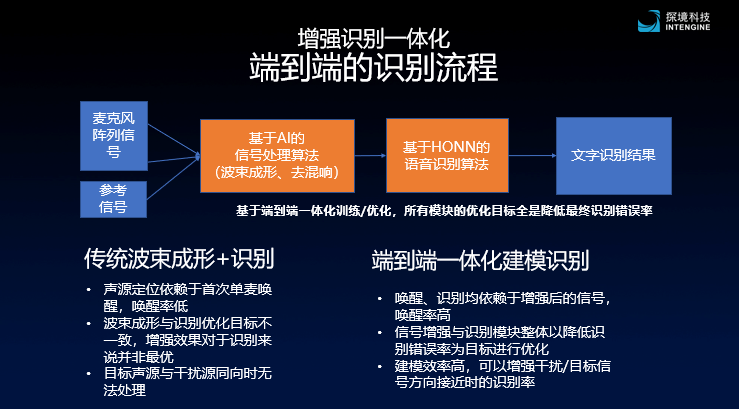
First, in the voice signal enhancement module, beamforming relies on sound source localization (DOA), and DOA relies on single microphone wake word detection. The far-field environment wake-up word detection uses single-signal signals without enhanced signals, which will affect the final wake-up rate.
-
Secondly, the traditional array processing algorithms include multiple steps of noise reduction, signal enhancement, and recognition. These links do not optimize the goal of reducing the recognition rate. The optimization goal is to improve the hearing comfort of the human ear and the final The recognition rate is not completely equivalent, and there will be cases of incompatibility.
-
Again, because the entire process requires very high consistency of microphones and capacitors, material costs are increased. “Sometimes everyone does a good job in the laboratory, but after the mass production, it is found that the recognition rate deteriorates because the requirements for beamforming and sound source localization are high. Once there is a fluctuation, it will affect the recognition effect. < / li>
-
In addition, the principle of the beamforming algorithm is to enhance the signal strength in the beam in a specific direction and attenuate the signal amplitude outside the beam. When the directions of the interference sound source and the target sound source are very close, both are in the same beam, and the signal and noise are enhanced at the same time, which cannot improve the signal-to-noise ratio.
As a result, traditional microphone array processing algorithms are not ideal.
The solution idea proposed by Prospecting Technology is to integrate enhancement and recognition to achieve end-to-end recognition, and launch an end-to-end AI dual wheat algorithm based on FCSP, giving up traditional digital signal processing algorithms to do Speech enhancement, and AI algorithms based on neural networks are used for signal enhancement. At the same time, during the model training, the “attention-enhancing” learning method is adopted, which can sensitively detect arousal words and command words. Even if the interference signal is close to the target signal direction, it can also wake up and recognize sensitively. Similar to a noisy environment, if someone shouts his name, he may respond quickly.
On the whole, the Tornado 612 solution improves the signal processing capability of Domai and the recognition rate and effective computing power in high-noise environments. Lu Yong said that 612 is mainly targeted at the smart home field, with expected shipments in the tens of millions.
Commercialization has been completed in 2 years, and mass production has exceeded one million
Exploration Technology was established in 2017, and initially completed the prototype of the SFA architecture in 2018. Q3 voice chip 611 was streamed in 2018, and mass production was achieved in Q1 2019. So far, the voice recognition solution has shipped more than one million Level, the entire commercialization landing time is about 2 years.
Li Tongzhi, vice president of Prospecting Technology, told the company that after launching the SFA architecture in early 2018, the company chose to launch the voice chip first due to research and development difficulties and market factors.
In terms of R & D difficulty, Li Tongzhi said that the voice on storageThe chip does not exceed 200M, but the image chip usually needs more than 1G, which increases the complexity of the chip design. Secondly, due to the large amount of image information, more interfaces are required, and higher integration is required. In terms of computing power requirements, the computing power of the image chip is 4T Ops, while the voice chip is tens of G, which is a difference of tens of times. Taken together, the difficulty of developing a voice chip is lower than that of an image chip. The cycle investment of an image chip is about 2-3 times that of a voice chip.
In addition, a very important reason is that Prospecting Technology believes that the voice chip market is more clear than images, and it can clearly benchmark the IOT market. Demand will be more than the image field that mainly takes the TO B route. More and larger.
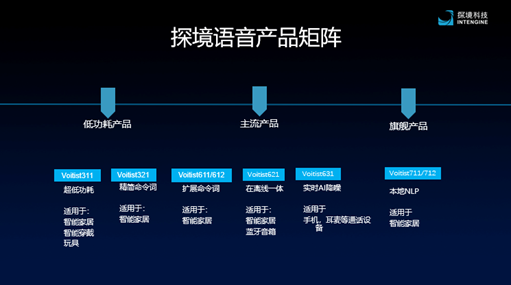
In addition, at the meeting, the exploration technology mentioned off-line integrated solutions, and announced a product matrix for different scenarios.
At present, the profit scale of exploration technology is in the tens of millions, and there are more than 30 partners, including Midea, Haier, Shiqiang Technology, and Avatar Intelligent Control. In addition, according to Lu Yong, the exploration chip graphics chip has been successfully streamed in Q4 2019, with a core energy efficiency ratio of 800 IPS / w, and the image chip has also started to generate revenue in some areas.
Lu Yong mentioned that the future exploration technology will face more scenarios, promote the end-cloud integration strategy, and launch more off-line integration solutions.
Further reading
The AI chip lasts: a good story, but not a good business?
(Image source in this article: Exploration Technology)
-