Where does that prejudice come from? This problem is closely related to the core technology behind artificial intelligence-machine learning.
Editor’s note: This article is from Tencent Research Institute , author S Jun. ai .
Topic: Algorithmic bias: the invisible “arbiter”
We live in an era surrounded by AI algorithms. The advancement of technology has caused AI to break through the past use boundaries, enter the deeper decision-making field, and have an important impact on our lives. AI has become a recruitment interviewer, a sentencing assistant, and a teacher who adjudicates admission applications … This technology has undoubtedly brought us convenience. But at the same time, a problem that can not be ignored has also surfaced-algorithmic bias.
BBC reported on November 1st that Apple co-founder Steve Wozniak posted on social media that Apple ’s credit card gave him 10 times the credit limit of his wife, although the couple did Individual bank account or any personal assets. This makes one wonder whether there is sex discrimination in Apple’s credit limit algorithm?
In fact, it is not only women who are discriminated against, but also the areas where prejudice spreads far beyond the amount of bank loans. In this close-up, we will start with typical types of algorithmic biases and investigate them in detail. How do biases get into the machine brain, and how will we fight against them in the future?
Typical categories of algorithm bias
■ Insufficient technological inclusion
Ghanaian scientist Joy Buolamwini accidentally discovered that face recognition software could not recognize her existence unless a white mask was put on. Feeling this, Joy launched the Gender Shades study and found that IBM, Microsoft, and Face ++ face recognition products all have different degrees of “discrimination” between women and dark people (ie, women and dark people). The recognition accuracy rate is significantly lower than that of males and light-colored people), the maximum gap can reach 34.3%.
The essence of this problem is actually the lack of tolerance of facial recognition technology for different groups. Just like when we develop a product, it is easy to fit the usage habits of young and middle-aged people, and ignore the consequences of its use on the elderly or children, or exclude people with disabilities from users.
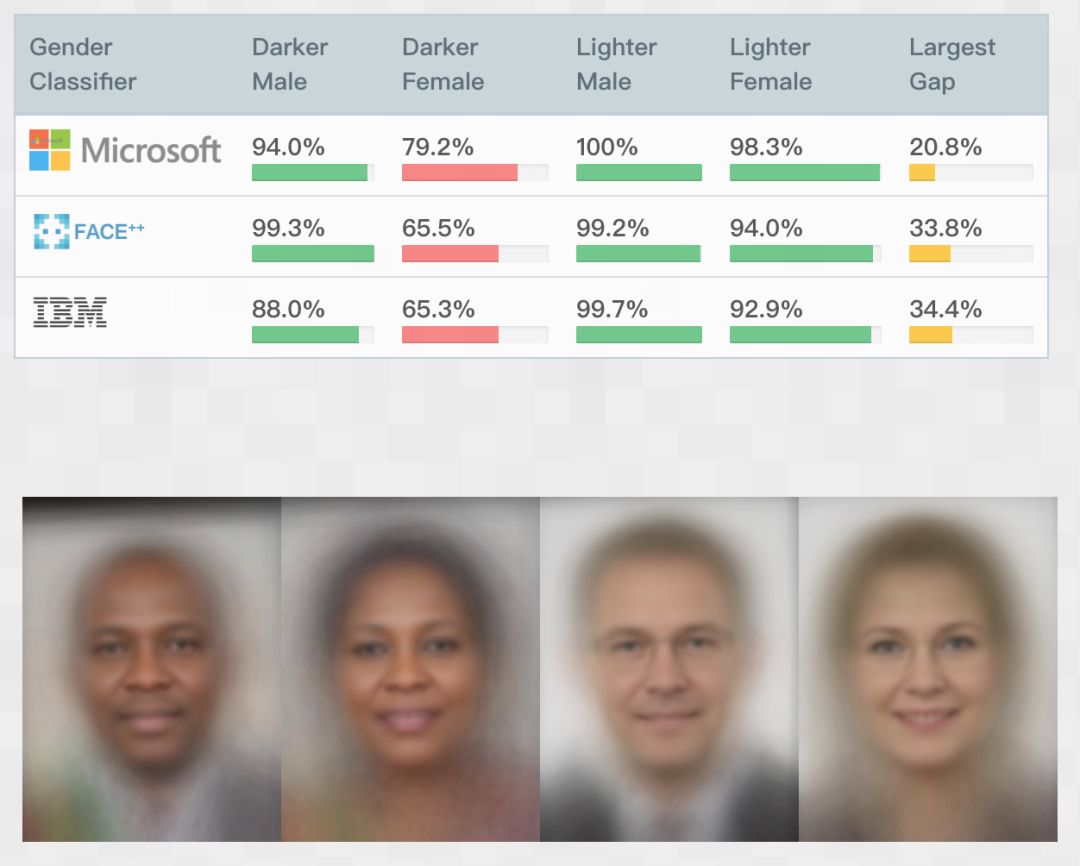
Picture source: Algorithm Justice League official website
■ Unfair forecasting and decision-making
If the issue of inclusion is more directed towards ethnic minorities or women, then unfair predictions and decision-making are more likely to happen to anyone. For example, recruitment bias. In November this year, HireVue, an AI interview tool used by Goldman Sachs, Hilton, Unilever and other famous companies, its decision-making preferences are incredible: AI can’t tell whether you frown because you are thinking about problems or are in bad mood Irritability); The Durham Police in the United Kingdom has used a crime prediction system for several years, setting the probability of blacks as criminals twice that of whites, and also likes to classify whites as low-risk, individual crimes. (DeepTech Deep Technology)
In today’s life, the field of AI participation in evaluation and decision-making is much more than that. In addition to crime and employment, it also includes financial, medical and other fields. AI decision-making relies on the learning of human decision-making preferences and results. Machine biases essentially project biases rooted in social traditions.
■ Display of prejudice
Type “CEO” in the search engine, there will be a series of male white faces; some people changed the keyword to “black girl”, and even appeared a lot of pornography. Tay, a robot developed by Microsoft, was delisted just one day after it was launched on Twitter because of user influence, racism and extreme speech. (THU Data School) This kind of prejudice is not only derived from learning in user interaction, but also being nakedly presented by AI products to a wider audience, thus creating a chain of prejudiced cycles.
Where does the bias of the algorithm come from?
Algorithms do n’t discriminate, and engineers rarely teach biases to algorithms. Where does that prejudice come from? This problem is closely related to the core technology behind artificial intelligence-machine learning.
The machine learning process can be reduced to the following steps, and there are three main steps to inject bias into the algorithm-data set construction, goal setting and feature selection (engineer), and data annotation (annotator).
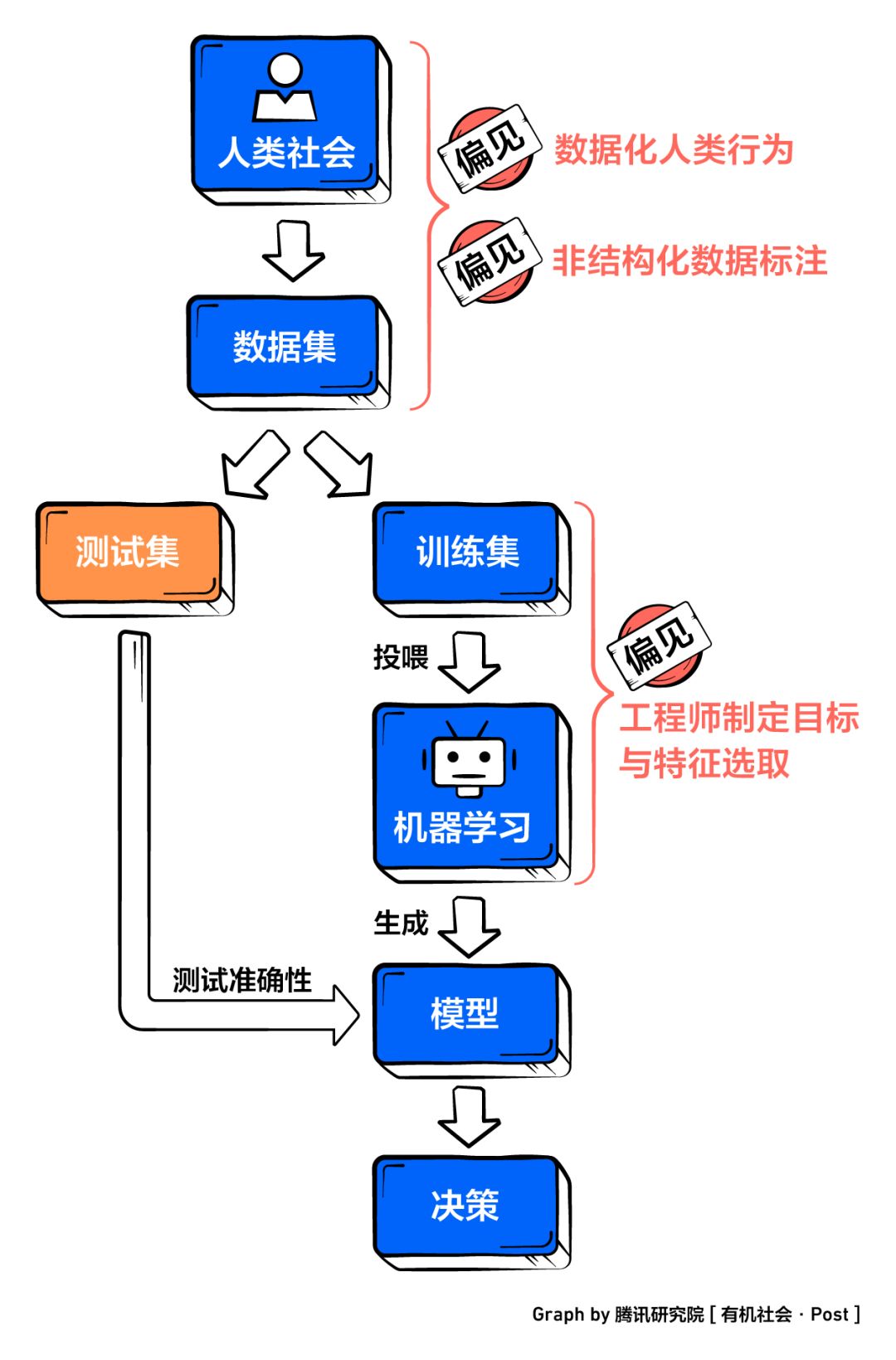
■ Dataset: Prejudiced soil
Data sets are the basis of machine learning. If the data sets themselves are not representative, they will not be able to objectively reflect the reality, and algorithm decisions will inevitably be unfair.
The common manifestation of this problem is the matching deviation. For the convenience of data collection, the data set tends to tend to more “mainstream” and available groups, so that, Uneven distribution at the gender level.
Facebook has announced that it has been tested by Labeled Faces in the Wild, one of the most well-known face recognition data sets in the world, with an accuracy rate of up to 97%. But when researchers looked at this so-called gold standard data set, they found that nearly 77% of men in this data set, and more than 80% are white. (All Media School) This means that the algorithm trained by this may have problems in identifying specific groups. For example, in Facebook photo recognition, women and black people may not be accurately marked.
Another situation is that existing social biases are brought into the data set. When the original data is the result of social prejudice, the algorithm will also learn the prejudice relationship.
Amazon found that the reason for the deviation in its recruitment system is that the original data used by the algorithm is the company ’s past employee data-in the past, Amazon hired more men. The algorithm learns this feature of the data set, so it is easier to ignore female job applicants in decision-making. (MIT Technology Review)
In fact, almost every database behind a machine learning algorithm is biased.
■ Engineer: rule maker
Algorithm engineers participate in the entire system from start to finish, including: machine learning goal setting, which model to use, what features (data labels) to select, data preprocessing, etc.
Inappropriate goal setting may have introduced bias from the beginning, such as the intention to identify criminals by face; however, more typical personal bias substitutions appear in the selection of data features.
Data tags are a bunch of determinants that help the algorithm achieve its goals. The algorithm is like a sniffer dog. When the engineer shows him the smell of a particular thing, it can find the target more accurately. Therefore, engineers will set tags in the data set to determine what content and model the algorithm should learn from the data set.
In Amazon ’s recruitment system, engineers may set tags such as “age”, “gender”, and “education level” for the algorithm. Therefore, when learning the past employment decision, the algorithm will recognize this part of the specific attributes and build a model based on it. When engineers think that “gender” is an important criterion, it will undoubtedly affect the algorithm’s response to data.
■ Marker: Unintentional ruling
For some unstructured data sets (such as a large number of descriptive text, pictures, videos, etc.), the algorithm cannot directly analyze them. At this time, it is necessary to manually label the data and extract the structured dimensions for training the algorithm. To give a very simple example, sometimes Google Photos will ask you to help determine whether a picture is a cat, then you have participated in the marking of this picture.
When the marker is facing the “cat”Dog” question, the worst result is simply a wrong answer; but if faced with “beauty or ugliness” torture, prejudice arises. As a data processor, markers are often asked to be subjective Value judgment, which has become a major source of prejudice.
ImageNet is a typical case: as the world ’s largest database for image recognition, many pictures on the website are manually annotated and labeled with various subdivisions. “Although it is impossible for us to know whether these labeled people themselves have such prejudices. But they define what” losers “,” sluts “and” criminals “should look like … The same problem may also occur in what seems On the label of ‘harmless’. After all, even the definitions of ‘man’ and ‘woman’ are still open for discussion. “(All Media School)
Trevor Paglen is one of the founders of the ImageNet Roulette project, which is dedicated to showing how opinions, prejudices, and even offensive opinions affect artificial intelligence. He believes: “Our way of labeling images is the product of our world view, and any classification system will reflect the values of the classifier.” In different cultural backgrounds, people have prejudices against different cultures and races.
The marking process transfers personal bias into the data and is absorbed by the algorithm, thus generating a biased model. Today, manual marking services have become a typical business model, and many technology companies have outsourced their massive data for marking. This means that algorithmic bias is being spread and amplified through a process of “invisibility” and “legalization”.
Editor’s summary
Because of the large number of applications of AI technology and the black box principle, algorithm bias has long become a hidden but widespread social hidden danger. It will bring injustice in decision-making, and face recognition technology will only benefit a part of people, and it will display a biased view in the search results …
But machines have never created prejudice independently. Prejudice is learned from several important links in machine learning: from the imbalance of the data set, to the bias of feature selection, to the subjectivity brought by manual marking. In the migration from man to machine, prejudice has learned some kind of “hidden” and “legitimate”, and has been constantly practiced and amplified.
But looking back, technology is just a mirror of society and people’s hearts. To some extent, algorithmic prejudice is like presenting the truth in dark corners and sounding the alarm in this moment when we think of progress and beauty. Therefore, when it comes to coping with algorithmic bias, part of the effort is to return to people. Fortunately, even self-discipline and governance attempts at the technical level can greatly reduce the degree of prejudice and avoid a large expansion of prejudice.
From gender discrimination to unfair recruitment, how can AI be treated fairly?
Algorithm is a mirror, reflecting many prejudices inherent in human society.
In 2014, Amazon ’s engineers set out to develop an artificial intelligence recruitment software that uses algorithms and data analysis to screen candidates, thereby avoiding the unique “emotional use” problem of human recruitment officers. It turned out to be counterproductive. Although the software avoids the problem of “emotional use”, it makes a bigger mistake in “prejudice”-the software writer writes the screening mode of the human recruitment officer into the algorithm, and the unconscious bias in the real world also brings in The machine.
With the continuous popularization of intelligent technology, algorithms have become a trend. Avoiding the prejudice of human society mapped into the algorithmic world is an important proposition in the current digital existence.
Previously, the tries to analyze the problems caused by algorithmic bias. This article focuses on combing some of the current solutions to algorithmic bias.
In the process of machine learning, algorithm bias will be infiltrated from three links: the composition of the data set is not representative, when engineers formulate algorithm rules, and markers deal with unstructured materials, there is a possibility of mixing in bias.
“After investigating 500 engineers in the field of machine learning, it was concluded that one of the biggest problems faced by machine learning engineers today is that they know that something went wrong, but they do n’t know exactly what went wrong. I don’t know why there is a problem. “Shen Xiangyang, former Microsoft’s executive vice president, pointed out.
Because the algorithmic bias is unknowable and untraceable, the task of anti-bias becomes tricky. Under the existing response system, whether it is a policy system, technological breakthroughs or innovative countermeasures, try to solve this problem that has surpassed technology from different perspectives.
Solution idea 1: Build a more fair data set
Unfair data sets are the soil of prejudice-if the data set used to train the machine learning algorithm cannot represent the objective reality, then the application results of this algorithm often have specificGroup discrimination and prejudice. Therefore, the most direct solution to the algorithmic bias is to adjust the originally uneven data set.
Revised data ratio: Use more equitable data sources to ensure fair decision-making. In June 2018, Microsoft collaborated with experts to revise and expand the dataset used to train the Face API. Face API is an API in Microsoft Azure that provides pre-trained algorithms to detect, recognize, and analyze attributes in face images. The new data reduces the recognition error rate between darker-skinned men and women by 20 times and the recognition error rate for women by 9 times by adjusting the proportions of skin color, gender, and age.
Some companies also try to optimize the data set by building a global community. Through the global community, large-scale collection of any information that an organization may be looking for, and in this combination of breadth and depth, this makes it possible to introduce completely different data to train AI systems to help overcome Algorithm bias and other issues.
Combination of “big data” and “small data”: to ensure accuracy based on the amount of data. The data set should not be limited to extensive collection, but rather accurate grasp. Just making a fuss about the amount of data often fails to bring more fair results, because big data analysis focuses on correlation, which leads to errors in the derivation of causality. The introduction of small data can partially solve this problem. Small data refers to the data form that focuses on individual users. It pays more attention to details and differences, can present more accurate data, and avoids errors when deriving causality. Therefore, combining information-rich big data with accurate information small data can avoid errors to a certain extent.
Autonomous test data set: detect bias in the data set. Scientists at the MIT Computer Science and Artificial Intelligence Laboratory (abbreviated as MIT SCAIL) published a paper entitled “Uncovering and Mitigating Algorithmic Bias through Learned Latent Structure” Demonstrated that DB-VEA (an unsupervised learning) AI system that can automatically eliminate data bias through resampling.
The model not only learns facial features (such as skin color, hair), but also other features such as gender and age, so the classification accuracy rate increases significantly, and the classification bias for race and gender decreases significantly.
It can be seen that building a more fair data set is undoubtedly one of the fundamental solutions to algorithmic bias, and also the direction of efforts of many companies and scholars, and there are indeed breakthroughs in this field.
Solution idea 2: Improve “algorithm transparency”
Although algorithm models are written by engineers, many times, humans do n’t understand how the computer has gone throughThe specific result is the “algorithm black box” problem in machine learning. Therefore, requiring enterprises to improve the transparency of algorithm models and find out the “cause” of biases has become one of the ways to solve the “black box” dilemma. Whether it is through the “other discipline” of policies and terms, or the ethical “self-discipline” or technological exploration of enterprises, when confronting algorithmic bias, they continue to focus on opening “black boxes.”
Self-discipline: corporate ethics
In the past two years, many large technology companies have issued principles for the application of artificial intelligence, all of which involve the governance of prejudice. These principles can be regarded as the starting point of the declaration and self-regulation of technology companies. Microsoft, Google and IBM all emphasize the transparency and fairness of the algorithm. It is worth noting that Microsoft has established an artificial intelligence and ethics (AETHER) committee to implement its principles, and plans to launch every artificial intelligence product to be subject to artificial intelligence ethics review in the future.
Some companies have adopted mechanisms other than committees. Google ’s launch of Model Cards is also a response to increased transparency. Model Cards is similar to the algorithm manual, explaining the algorithm used, telling its advantages and limitations, and even the results of operations in different data sets.
Heru: transparency of supervision process and result justice
The “EU General Data Protection Regulation” (GDPR), which officially came into effect on May 25, 2018, and the “Data Ethics Framework” updated by the British government on August 30, 2018, require algorithms to have certain openness and transparency With interpretability. On April 10, 2019, members of both houses of the United States Congress proposed the Algorithmic Accountability Act, which requires large technology companies to assess the impact of their automatic decision-making system and eliminate the reasons for race, color, religion, political belief, gender, or other Bias due to differences in characteristics.
Some public welfare organizations are also aware of the dangers of algorithmic bias and help companies establish mechanisms to ensure the fairness of algorithms. Algorithm Justice League (Algorithm Justice League) summarizes and condenses the behaviors that companies should abide into agreements that can be signed, through the design, development and deployment of accountable algorithms, improve the existing algorithms in practice and check the achievements of enterprises to improve.
And this method did urge the algorithm correction: its founder Joy Buolamwini feedback the results after evaluating the IBM algorithm, and received an IBM response within a day that it will solve thisproblem. Later, when Buolamwini re-evaluated the algorithm, it was found that the accuracy of the IBM algorithm for minority recognition has improved significantly: the accuracy of identifying dark men jumped from 88% to 99.4%, and the accuracy of dark women from 65.3% Rose to 83.5%.
“Algorithm transparency” is not a perfect answer?
However, there are still some limitations in improving the transparency of algorithms through policy regulations and ethical guidelines. First of all, the algorithm must be interpretable and there is a strong conflict between the interests of possible companies. Rayid Ghani, director of the Center for Data Science and Public Policy at the University of Chicago, believes that simply publishing all the parameters of a model does not provide an explanation of its working mechanism. In some cases, revealing too much information about how the algorithm works may disappoint. Well-intentioned people attack this system. A paper in December 2019 also pointed out that the two major technologies that explain the black box algorithm, LIME and SHAP, may be hacked, which means “the interpretation made by AI may be deliberately tampered, resulting in people ’s The explanation it gave lost trust. ”
Second, the core of the accountability bill is to facilitate self-examination and self-correction. However, this top-down system will undoubtedly increase the huge workload of the enterprise. In the round of review and evaluation, the technical progress will be constrained, and the innovation ability of the enterprise will also be affected.
Solution idea 3: Anti-prejudice in technological innovation
When prejudice is hidden in countless codes, engineers think of using technology itself to solve technical problems. This approach is not to start from the source of prejudice, but to creatively use technical means to detect and remove prejudice.
Word embedding solves gender bias in search: Microsoft researchers found from texts in news and webpage data that there are some obvious characteristics when establishing associations between words, such as “sassy” and “knitting” ) “Is closer to women, while” hero “and” genius “are closer to men. The reason for this phenomenon is that the benchmark data set used to train the algorithm-usually data from news and web pages-itself, there is a “gender bias” caused by language habits, the algorithm also naturally “inherited” To understand the gender differences in human understanding of these words. Microsoft has proposed a simple and easy solution: in the word embedding, delete the judgment dimension that distinguishes “he” and “her” to reduce the “biased display”. Of course, this “simple and brutal” method can only be used in the field of text search. In more practical application scenarios, the “black box” feature of artificial intelligence makes gender or race linked to more and more complex parameters, so it is difficult to pass Delete directly to complete the elimination of bias.
Discover system defects through differential testing: Columbia University researchers have developed a software called DeepXplore, which canMake mistakes by “coaxing” the system to expose the flaws in the algorithm’s neural network.
DeepXplore uses differential testing (differential testing), a concept that compares multiple different systems and looks at their corresponding output differences: DeepXplore looks at things differently, if other models are consistent with a given input Prediction, and only one model makes a different prediction about this, then this model will be judged to have a loophole. This research has made an important contribution to opening the black box, because it can expose almost 100% of the problems that may arise in the algorithm by activating almost 100% of the neural network.
Bias detection tool: In September 2018, Google introduced a new tool, What-If, which is a tool for detecting bias in TensorBoard. Using this tool, developers can explore the importance of machine learning models through interactive visual interfaces and counterfactual reasoning, find out the causes of misclassification, determine decision boundaries, and detect algorithm fairness. Similarly, IBM has also opened its bias detection tool AI Fairness 360 toolkit, which includes more than 30 fairness indicators and 9 bias mitigation algorithms. Researchers and developers can integrate the tool into their own machine learning models to detect and Reduce possible prejudice and discrimination.
Technology itself is used to combat prejudice and is a highly operable method, because engineers are often good at solving practical problems with technology. However, judging from the current results, most of the technological breakthroughs are still only in the primary stage, staying in the detection bias, eliminating the bias may still be the next stage of efforts.
Written at the end:
The causes of prejudice in real society are intertwined, and the movement to eliminate prejudice is endless and has not been completely eliminated. Right now, prejudice is turned into a digital memory, sly and hidden in every accidental double-click, every tiny decision, but it can significantly affect the way people are treated.
A fairer data set, more timely error detection, and a more transparent algorithm process … The collaborative efforts of technology companies, scientific research institutions, regulatory authorities, and third-party organizations declare war on algorithmic bias. These measures may not completely eliminate prejudice, but they can greatly prevent technology from magnifying the prejudices inherent in society.
Compared with blaming technology bias entirely on technology, it is more important to realize that technology, as a tool, should have boundaries. The depth of its penetration into daily life and the extent to which decisions are adopted require careful decision-making.
Reference:
1. “Shen Xiangyang’s inauguration of Tsinghua’s speech: Humans know nothing about how AI makes decisions” AI frontline https://mp.weixin.qq.com/s/sezAachD_dhB3wrDTTZ8ng
2. “The algorithm bias blames the data set?MIT correction algorithm automatically recognizes “vulnerable groups” “Heart of the machine
https://www.jiqizhixin.com/articles/2019-01-28-11
3. “Applause launches new AI solution dedicated to solving algorithmic bias” NetEase Intelligence https://mp.weixin.qq.com/s/oG9GtlplwXrNkGnXqEZOWA
4. “” Algorithm is biased, better than people? “In fact, it has a wide range of influence! 》 THU Data School
https://mp.weixin.qq.com/s/_ArUXZGT6_iJ_Nggrit8-A
5. “Algorithm Bias Detective” Lei Feng Net AI Technology Review
https://www.leiphone.com/news/201812/b4FLYHLrD8wgLIa7.html
6. “Shen Xiangyang: Microsoft Research Institute-Endless search, creating responsible artificial intelligence for all human beings” Microsoft Technology https://www.sohu.com/a/337918503_181341
7. “DeepXplore: Automated White Box Testing of Deep Learning Systems” AI Frontline
https://mp.weixin.qq.com/s/ZlVuVGW_XA_MTgBJhMmqXg