Multi-task learning makes AI more practical value (ID: unity007) , author: sea monster.
When it comes to multi-task learning in the field of AI, many people may immediately think of general artificial intelligence. A common understanding, like a nursing robot like Dabai in “Super Marine”, can not only perform medical diagnosis, but also understand human emotions, and can complete various complex tasks like accompanying robots.
However, after all, Dabai is only a product of science fiction movies. Most of the existing AI technology is still in the stage of single intelligence, that is, a machine intelligence can only complete a simple task. In industrial robots, paint spraying can only be used for paint spraying, and transport can only be used for transport; smart cameras that recognize human faces can only be used for human faces. Once humans wear masks, they must readjust the algorithm.

Of course, letting a single agent perform multiple tasks is also a hotspot in current AI research. Recently, the best performance in reinforcement learning and multi-task learning algorithms is an agent called Deep57 from DeepMind, which is implemented in all 57 Atari games in the arcade learning environment (ALE) dataset. Beyond human performance.
Of course, multi-task learning is not only used in game strategy. Compared to AI at this stage, we humans are masters of multi-task learning. We do not need to learn tens of thousands of data samples to know a certain type of thing, and we do not have to learn from the beginning for each type of thing, but can grasp similar things by touch.
AI can indeed easily crush humans on the basis of single intelligence, for example, it can recognize thousands of human faces; but AI should match the universal ability of humans in multi-task learning.
What is multi-task learning?
Multi-Task Learning (MTL), in simple terms, is a way for machines to imitate human learning behavior. The human learning method itself is generalized, that is, it can be transferred from learning the knowledge of one task to other related tasks, and the knowledge skills of different tasks can help each other to improve. Multi-task learning involves learning multiple related tasks in parallel at the same time.At the same time, the degree of back-propagation is used to improve the generalization ability by using the specific field information contained in the training signal of the relevant task.
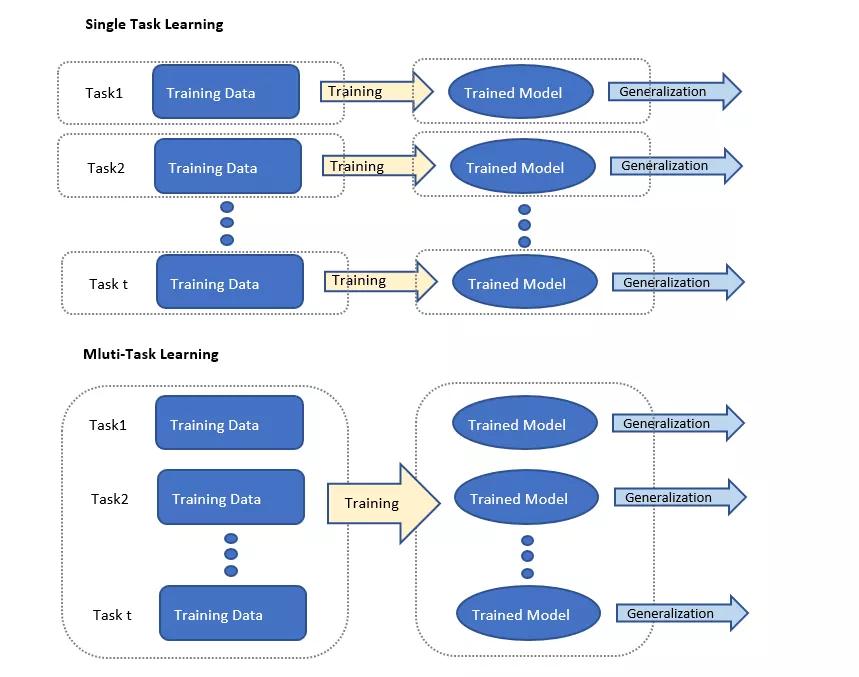
(Single-task learning and multi-task learning model comparison diagram)
Make an image analogy. We know that humans are not as good at running as tigers and leopards, not as good at crawling as apes and monkeys, or swimming like whales and dolphins, but humans can only run, climb, and swim at the same time. Used in artificial intelligence and human intelligence, we usually think that AI is better at performing on a single task and surpassing human experts, like AlphaGo; and humans may be competent in various tasks.
MTL is to allow artificial intelligence to realize this kind of human ability. By sharing useful information in the learning of multiple tasks, a more accurate learning model that helps the learning of each task is improved.
What needs to be noted here is the difference between multi-task learning and transfer learning. The goal of transfer learning is to transfer knowledge from one task to another. Its purpose is to use one or more tasks to help another target task improve, and MTL hopes that multiple tasks can help each other improve each other.
Here we have to figure out the two characteristics of MTL:
First, the tasks are relevant. The relevance of tasks means that there are certain correlations in the completion modes of several tasks. For example, in face recognition, in addition to the recognition of facial features, it is also possible to estimate and recognize gender and age, or, in different Several types of games have identified some common rules, and this correlation will be coded into the design of the MTL model.
Second, there are different classifications of tasks. The task classification of MTL mainly includes supervised learning tasks, unsupervised learning tasks, semi-supervised learning tasks, active learning tasks, reinforcement learning tasks, online learning tasks and multi-view learning tasks, so different learning tasks correspond to different MTL settings.
Shared representation and feature generalization, two keys to understanding the advantages of MTL
Why may the learning effect of training multiple tasks simultaneously on a neural network be better?
We know that a deep learning network is a neural network with multiple hidden layers, which transforms input data into non-linear, more abstract feature representations layer by layer. And the model parameters of each layerThe number is not artificially set, but is learned during the training process given the parameters of the learner, which gives the multi-task learning room to show its punches and has the ability to learn the common characteristics of multiple tasks during the training process.
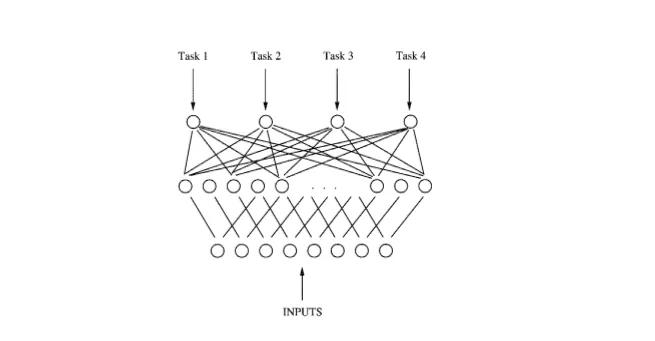
For example, in the above MTL network, the backward propagation acts on 4 outputs in parallel. Since the four outputs share the bottom hidden layer, the feature representations used in a certain task in these hidden layers can also be used by other tasks, prompting multiple tasks to learn together. Multiple tasks are trained in parallel and share the feature representations that have been learned by different tasks. In this way, multi-task information helps share hidden layers to learn a better internal representation, which becomes the key to multi-task learning.
So how does MTL produce results?
Inductive bias is introduced in the MTL method. Inductive bias has two effects. One is mutual promotion. The relationship between multi-task models can be regarded as mutual prior knowledge, also known as inductive transfer. With the a priori assumption of the model, it can be more A good effect of improving the model; another effect is the constraint effect, with the help of noise balance between multiple tasks and characterization bias to achieve better generalization performance.
First of all, the introduction of MTL can make deep learning less dependent on large amounts of data. Tasks with a small number of samples can learn some shared representations from tasks with a large sample size to alleviate the sparse problem of task data.
Secondly, the direct mutual promotion of multi-tasking is reflected in: ①The characteristics of multiple models make up for each other. For example, in the webpage analysis model, improving the click-through rate prediction model can also promote the conversion model to learn deeper features; ②Note Force mechanism, MTL can help the training model focus on important features, and different tasks will provide additional evidence for this important feature; ③ “eavesdropping” of task features, that is, MTL can allow different tasks to “eave” each other’s Features, directly predict the most important features by “hinting” the training model.
Once again, the mutual constraint of multitasking can improve the generalization of the model. On the one hand, the noise balance of multitasking. The different noise patterns of the multi-task model allow multiple task models to learn generalized representations, avoiding overfitting of individual tasks. Joint learning can obtain better representations through average noise patterns; on the other hand, representation bias. MTL’s preference for characterization can cause model bias. But this will help the model generalize to new tasks in the future. Under the premise that the tasks are the same, you can learn enough hypothesesTime, get better generalization performance in some new tasks in the future.
Industry scenes are landing, how does MTL solve real-world problems
Because MTL has the advantages of reducing the dependence of big data samples and improving the generalization performance of models, MTL is being widely used in model training of various convolutional neural networks.
First of all, multi-task learning can learn the shared representation of multiple tasks. This shared representation has a strong abstract ability, can adapt to multiple different but related goals, and can usually make the main task get better generalization ability .
Secondly, due to the use of shared representation, when multiple tasks simultaneously make predictions, the number of data sources and the size of the overall model parameters are reduced, making prediction more efficient.
We take the application of MTL in computer vision, such as target recognition, detection, segmentation, etc., as an example.
For example, facial feature point detection. Because facial features may be affected by occlusion and posture changes. MTL can improve the robustness of detection, rather than treat the detection task as a single and independent problem.
Multi-task learning hopes to combine optimized facial feature point detection with some different but subtle related tasks, such as head pose estimation and facial attribute inference. Face feature point detection is not an independent problem, its prediction will be affected by some different but subtle related factors. For example, a child who is laughing will open his mouth, effectively discovering and using this relevant facial attribute will help to detect the corner of the mouth more accurately.
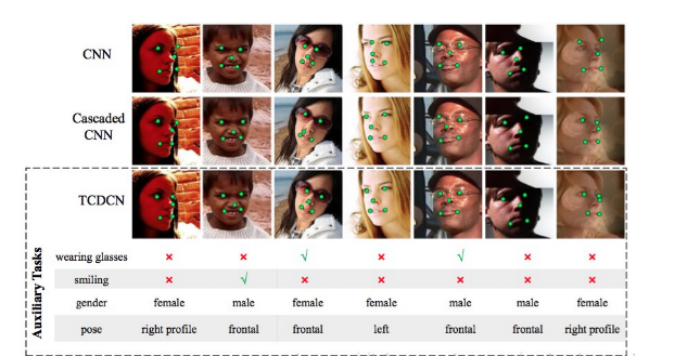
As shown above, in the face feature point detection (TCDCN) model, in addition to the task of detecting feature points, there are four auxiliary tasks of identifying glasses, smiling faces, gender, and posture. By comparing with other networks, we can see that auxiliary tasks make The detection of the main task is more accurate.
MTL has different applications in different fields, its models are different, and the application problems it solves are also different, but there are some characteristics in their respective fields. In addition to the computer vision field described above, there are also things like biological information Many fields including learning, health informatics, speech, natural language processing, web spam filtering, web page retrieval and pervasive computing can use MTL to improve the effectiveness and performance of their respective applications.
For example, in bioinformatics and health informatics, MTL is used to identify characteristic mechanisms of response to treatment targets, to detect causal genetic markers through association analysis of multiple groups, and through sparse Bayesian models Automatic correlation featureSign to predict the cognitive outcome of neuroimaging measurements of Alzheimer ’s disease.
Application in speech processing. In 2015, a researcher shared a paper “Deep Neural Network Speech Synthesis Based on Multitask Learning” at the International Conference on Acoustics, Speech and Signal Processing (ICASSP), and proposed a multi-task stacked deep neural network. It consists of multiple neural networks. The previous neural network uses the output of its uppermost layer as the input of the next neural network for speech synthesis. Each neural network has two output units. By sharing the hidden between the two tasks Layer, one for the main task and the other for the auxiliary task, so as to better improve the accuracy of speech synthesis.
In network Web applications, MTL can be used to share a feature representation for different tasks and learn to improve ranking in web search; MTL can be used to find the most converted conversions in ads through scalable layered multi-task learning algorithms Issues such as hierarchy and structural sparsity.
In general, in these MTL application fields, feature selection methods and deep feature conversion methods are widely used by researchers. Because the former can reduce the data dimension and provide better interpretability, while the latter can obtain good performance by learning powerful feature representations.

MTL is being widely used in more and more fields as a means to improve the learning ability of neural networks. This is actually the normalized scenario of AI in practical applications in many industries.
We can finally trace the source and reflect on the fact that the reason why human beings can have the flexible application of multi-task learning is precisely because the environment is under the condition of multi-features and noise, which inevitably requires that we humans must Able to transfer a priori learning ability by analogy. If artificial intelligence only stays on the basis of single intelligence, and establishes a separate model for each type of knowledge or task, it may still be just a set of “artificially mentally disabled” mechanical systems in the end. Come the joke.
When the future of AI can truly be as proficient as humans in terms of integration, but also overcome human cognitive bandwidth and some cognitive biases, then the road to AGI may usher in a glimmer of light. Of course, this road is still quite far away.