0px; ‘> is a small amount to stabilize the value. Following this line of thought, we designed the AdaIN-ResBlock-based style fusion module Style Mix Block to inject ID information increments into content extracted from the source face through AdaIN at multiple spatial scales. We also adopted a training mode based on information increment: by mixing a part of the training data of the same image of the source and target faces, the injected style information is constant μ _ diff = 0, σ _ diff = 1. This scheme greatly improves the convergence speed of the model when learning reconstruction loss, and suppresses most of the artifacts caused by “face reconstruction”. Figure 4 shows the detailed structure of Style Mix Block.
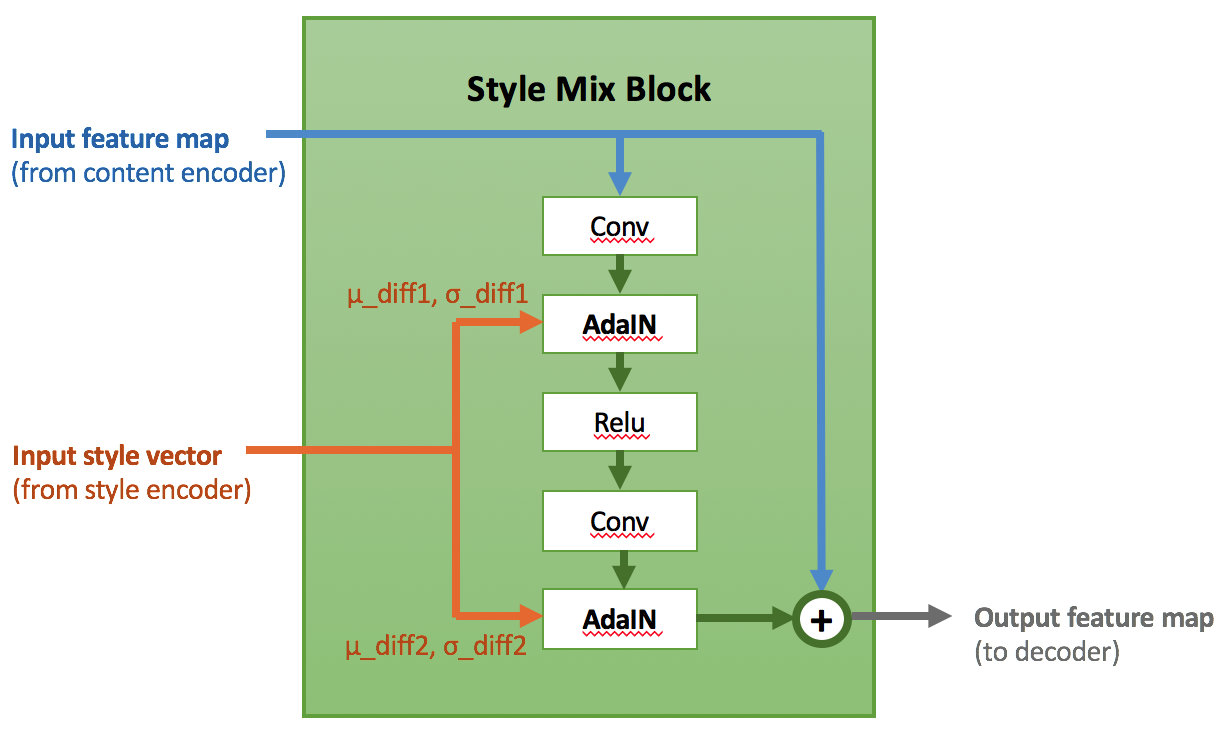
Figure 4. Details of Style Mix Block
But here, the BIGO algorithm team’s thinking about the ID injection scheme of the target face is still not over. The face change in the real scene, the original face and the target face will certainly not be as tidy as the ID photo, but often involve large-scale pose conversion or being blocked by hat glasses. In this case, there is a problem of inaccuracy in the information increment itself, which leads to a situation in which the result of changing faces is not like the target face in the actual effect. After intense discussion, we made a bold decision: the original feature G used to describe the ID information G , directly concatenate (Concatenate) to Style Mix Block features, and send this overall feature to Decoder to generate the final result. The overall network architecture is shown in Figure 5.
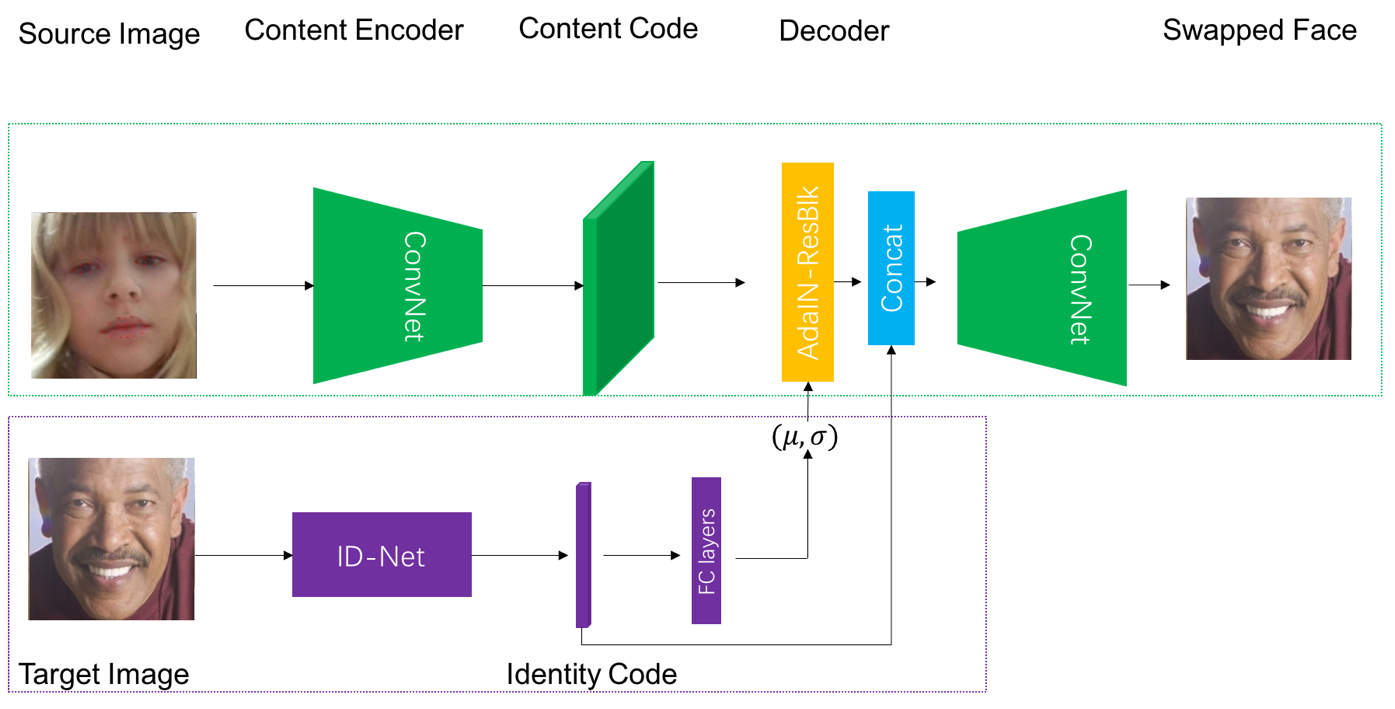
Figure 5. The core structure of FaceMagic face change < / span>
Fusion to you and me
The story is here, but it is still just the beginning, Where is the next question?
This involves some of the essence of the adversarial generation network. We often say that the adversarial generation network is essentially learning the characteristic manifold of real samples. During the generation, it selects a stream by selecting a set of random variables as seeds. The points on the shape are mapped onto the image space. This leads to the fact that although we can guarantee that a generated image is “true and natural”, it is difficult to guarantee continuity over a series of video frames. For example, in the scene of large-scale pose conversion, it is easy to appear that the pose information of the source face providing content is “lost”; in addition, the ID information of the source face will also have disturbances in the video itself, and these disturbances It will be further amplified by the injection operation. These circumstances have led to discontinuous situations such as posture swing or skin tone light shake when performing video frame-by-frame operations.
Here we use Pose Constraint and Skipping connection to alleviate the continuity problem in the video face change, as shown in the red part of Figure 6:
1) Pose Constraint: We use the landmarks of the face to strongly constrain the pose difference between the source face and the generated face. In this way, even if the source face has a large-scale pose conversion in some frames, the generated one will still be constrained to the source face’s pose.
2) Skipping Connection: In order to allow the generated image to stably retain the characteristics of the source image, we try to directly implant some low-level features of Encoder into the features of Decoder directly through Skipping Connection.
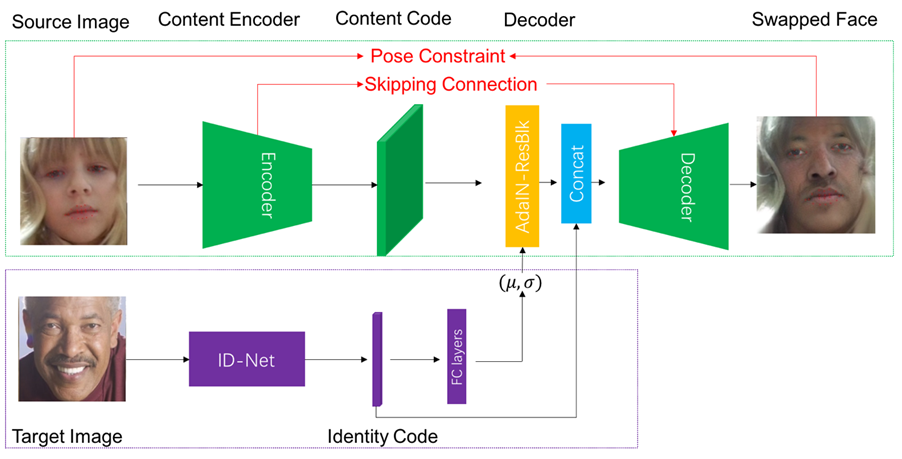
Figure 6. The final system structure of FaceMagic face change
Stop balance
We first make a small summary. At present, we have a lot of modules, and our total loss can be written in the following form:
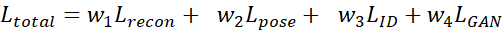
Obviously, increasing the weight of L_recon and L_pose can make the generated face retain the characteristics of the source face more. Increasing the weight of L_ID will migrate more target identity characteristics The weight of L_GAN is used to ensure that the generated face is as real and natural as possible. So, finally, can we start adjusting parameters happily?
Obviously, the ultimate balance is not obtained by adjusting the parameters. After digging deep into L_ID, the algorithm classmates of BIGO found that: for two people who look a bit like, the result after face change can hardly see the change visually, because their ID feature distance is originally small, if If only the simple l2 loss or cos similarity is used, the network will punish this part very little, but simply increasing the weight of L_ID will make the training of the entire network difficult. In order to solve this problem, we propose to measure the relative ID distance of the face-changing effect. To put it simply, it is to compare the distance difference between the source face and the target face before and after the face change. It can be expressed as:
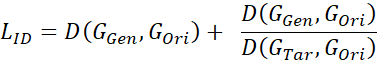
Among them, it is l2 loss or cos similarity. The first half of the formula is the original ID information loss, and the second half is the comparison loss.
Conclusion
Through the continuous efforts of the students of the BIGO algorithm team, we have overcome various technical difficulties and achieved FaceMagic, a real-time, highly realistic and natural video face change tool. But we will never stop here to rest, and we will continue to move forward in pursuit of ideals and technology.

Figure 7: Effect display, from left to right: source face, target Face, generate face
References
1. Volker Blanz, Kristina Scherbaum, Thomas Vetter, and Hans-Peter Seidel. Exchanging faces in images. In Computer Graphics Forum, volume 23, pages 669–676. Wiley Online Library, 2004. 1, 2, 3 < / p>
2. Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems (NPIS), pages 2672–2680, 2014.
3. Dmitri Bitouk, Neeraj Kumar, Samreen Dhillon, Peter Belhumeur, and Shree K Nayar. Face swapping: automatically replacing faces in photographs. ACM Trans. on Graphics (TOG), 27 (3): 39, 2008. < / p>
4. Justus Thies, Michael Zollhofer, Marc Stamminger, Chris- tian Theobalt, and Matthias Nießner. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2387–2395, 2016.
5. Volker Blanz, Sami Romdhani, and Thomas Vetter. Face identification across different poses and illuminations with a 3d morphable model. In Int. Conf. on Automatic Face and Gesture Recognition (FG), pages 192–197, 2002.
6. Supasorn Suwajanakorn, Steven M Seitz, and Ira Kemelmacher-Shlizerman. Synthesizing obama: learning lip sync from audio. ACM Transactions on Graphics (TOG), 36 (4): 95, 2017.
7. Yuval Nirkin, Iacopo Masi, Anh Tran Tuan, Tal Hassner, and Gerard Medioni. On face segmentation, face swapping, and face perception. In Automatic Face & Gesture Recognition (FG), 2018 13th IEEE International Conference on, pages 98–105. IEEE, 2018.
8. Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
9. Albert Pumarola, Antonio Agudo, Aleix M Martinez, Al- berto Sanfeliu, and Francesc Moreno-Noguer. Ganimation: Anatomically-aware facial animation from a single image. In Proceedings of the European Conference on Computer Vision (ECCV) , pages 818–833, 2018.
10. Enrique Sanchez and Michel Valstar. Triple consistency loss for pairing distributions in gan-based face synthesis. arXiv preprint arXiv: 1811.03492, 2018.
11. Hyeongwoo Kim, Pablo Carrido, Ayush Tewari, Weipeng Xu, Justus Thies, Matthias Niessner, Patrick Pe ́rez, Chris-tian Richardt, Michael Zollho ̈fer, and Christian Theobalt. Deep video portraits. ACM Transactions on Graphics (TOG ), 37 (4): 163, 2018.
12. Ryota Natsume, Tatsuya Yatagawa, and Shigeo Morishima. Rsgan: face swapping and editing using face and hair representation in latent spaces. arXiv preprint arXiv: 1804.03447, 2018.
13. Nirkin Y, Keller Y, Hassner T. Fsgan: Subjectagnostic face swapping and reenactment. In Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2019: 7184-7193.
14. Gatys L A, Ecker A S, Bethge M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). 2016: 2414-2423.
15. Huang X, Belongie S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2017: 1501-1510.
16. Karras T, Laine S, Aila T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019: 4401-4410.
17. Parkhi O M, Vedaldi A, Zisserman A. Deep face recognition [J]. 2015.
We first make a small summary. At present, we have a lot of modules, and our total loss can be written in the following form:
Obviously, increasing the weight of L_recon and L_pose can make the generated face retain the characteristics of the source face more. Increasing the weight of L_ID will migrate more target identity characteristics The weight of L_GAN is used to ensure that the generated face is as real and natural as possible. So, finally, can we start adjusting parameters happily?
Obviously, the ultimate balance is not obtained by adjusting the parameters. After digging deep into L_ID, the algorithm classmates of BIGO found that: for two people who look a bit like, the result after face change can hardly see the change visually, because their ID feature distance is originally small, if If only the simple l2 loss or cos similarity is used, the network will punish this part very little, but simply increasing the weight of L_ID will make the training of the entire network difficult. In order to solve this problem, we propose to measure the relative ID distance of the face-changing effect. To put it simply, it is to compare the distance difference between the source face and the target face before and after the face change. It can be expressed as:
Among them, it is l2 loss or cos similarity. The first half of the formula is the original ID information loss, and the second half is the comparison loss.
Conclusion
Through the continuous efforts of the students of the BIGO algorithm team, we have overcome various technical difficulties and achieved FaceMagic, a real-time, highly realistic and natural video face change tool. But we will never stop here to rest, and we will continue to move forward in pursuit of ideals and technology.
Figure 7: Effect display, from left to right: source face, target Face, generate face
References
1. Volker Blanz, Kristina Scherbaum, Thomas Vetter, and Hans-Peter Seidel. Exchanging faces in images. In Computer Graphics Forum, volume 23, pages 669–676. Wiley Online Library, 2004. 1, 2, 3 < / p>
2. Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems (NPIS), pages 2672–2680, 2014.
3. Dmitri Bitouk, Neeraj Kumar, Samreen Dhillon, Peter Belhumeur, and Shree K Nayar. Face swapping: automatically replacing faces in photographs. ACM Trans. on Graphics (TOG), 27 (3): 39, 2008. < / p>
4. Justus Thies, Michael Zollhofer, Marc Stamminger, Chris- tian Theobalt, and Matthias Nießner. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2387–2395, 2016.
5. Volker Blanz, Sami Romdhani, and Thomas Vetter. Face identification across different poses and illuminations with a 3d morphable model. In Int. Conf. on Automatic Face and Gesture Recognition (FG), pages 192–197, 2002.
6. Supasorn Suwajanakorn, Steven M Seitz, and Ira Kemelmacher-Shlizerman. Synthesizing obama: learning lip sync from audio. ACM Transactions on Graphics (TOG), 36 (4): 95, 2017.
7. Yuval Nirkin, Iacopo Masi, Anh Tran Tuan, Tal Hassner, and Gerard Medioni. On face segmentation, face swapping, and face perception. In Automatic Face & Gesture Recognition (FG), 2018 13th IEEE International Conference on, pages 98–105. IEEE, 2018.
8. Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
9. Albert Pumarola, Antonio Agudo, Aleix M Martinez, Al- berto Sanfeliu, and Francesc Moreno-Noguer. Ganimation: Anatomically-aware facial animation from a single image. In Proceedings of the European Conference on Computer Vision (ECCV) , pages 818–833, 2018.
10. Enrique Sanchez and Michel Valstar. Triple consistency loss for pairing distributions in gan-based face synthesis. arXiv preprint arXiv: 1811.03492, 2018.
11. Hyeongwoo Kim, Pablo Carrido, Ayush Tewari, Weipeng Xu, Justus Thies, Matthias Niessner, Patrick Pe ́rez, Chris-tian Richardt, Michael Zollho ̈fer, and Christian Theobalt. Deep video portraits. ACM Transactions on Graphics (TOG ), 37 (4): 163, 2018.
12. Ryota Natsume, Tatsuya Yatagawa, and Shigeo Morishima. Rsgan: face swapping and editing using face and hair representation in latent spaces. arXiv preprint arXiv: 1804.03447, 2018.
13. Nirkin Y, Keller Y, Hassner T. Fsgan: Subjectagnostic face swapping and reenactment. In Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2019: 7184-7193.
14. Gatys L A, Ecker A S, Bethge M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). 2016: 2414-2423.
15. Huang X, Belongie S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2017: 1501-1510.
16. Karras T, Laine S, Aila T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019: 4401-4410.
17. Parkhi O M, Vedaldi A, Zisserman A. Deep face recognition [J]. 2015.