Generate pictures with higher quality and more variety.
Editor’s note: This article comes from WeChat public account “qubit” (ID: QbitAI) author: fish sheep.
Look up, look down, look left, look right. Looking at food from all angles, it really makes people look hungrier.

And the fact that I do n’t know if it’s good or bad news: these foods never really existed.
Yes, this is a “pseudo gourmet book” generated by DeepMind’s latest LOGAN .
This GAN defeated the “strongest” BigGAN in its debut, became a new state-of-the-art, and increased FID and IS by 32% and 17% .
What concept? In short, it is that LOGAN can generate higher quality and more diverse pseudo photos.
On the left is BigGAN (FID / IS: 5.04 / 126.8), and on the right is LOGAN (FID / IS: 5.09 / 217).
With the same low FID, LOGAN is more reliable than BigGAN.
△ BigGAN on the left and LOGAN on the right
Regardless of FID, under similar high IS conditions, although the foods produced are all the same and the heat explodes, obviously LOGAN’s posture level will be more abundant.

And, DeepMind said: No need to introduce any architectural changes or other parameters.
Potential optimization
The method adopted by DeepMind is to introduce a latent optimisation inspired by CSGAN.
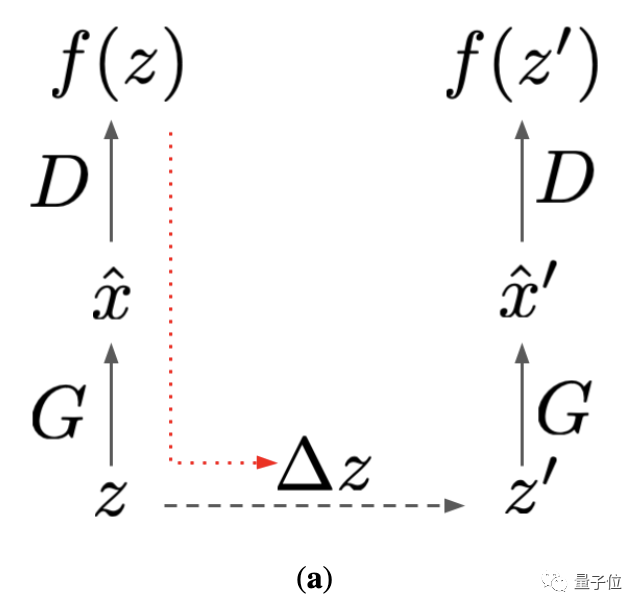
First, let the latent variable z be propagated forward through the generator and discriminator.
The gradient of the generator loss (red dotted arrow) is then used to calculate the improved z ‘.
In the second forward propagation, the optimized z ‘is used. Thereafter, the gradient of the latent optimization calculation discriminator is introduced.
Finally, use these gradients to update the model.

The core of this method, In fact, it is to strengthen the interaction between the discriminator and the generator to improve the adversity.
An important problem with gradient-based optimization in GAN is that the vector field generated by the discriminator and generator loss is not a gradient vector field. Therefore, there is no guarantee that the gradient descent will find a local optimal solution and be recyclable, which will slow down the convergence rate or cause mode collapse and mode jump phenomena.
Symplectic gradient adjustment algorithm (SGA) can find stable fixed points in ordinary games, and can improve the dynamics of gradient-based methods in confrontation. However, because the second derivative of all parameters needs to be calculated, SGA’sExpansion costs are high.

The potential optimization can only use the second derivative for the latent variable z and the discriminator and generator parameters, respectively, to achieve the effect of approximate SGA.
This eliminates the need to use computationally expensive second-order terms involving discriminator and generator parameters.
In short, potential optimizations most effectively couple the gradients of discriminators and generators, and are more scalable.
And, LOGAN benefits from a powerful optimizer. When researchers used natural gradient descent (NGD) for potential optimization, they found that this approximate second-order optimization method performed better than the exact second-order method.
While NGD is also costly in high-dimensional parameter spaces, it is effective for potential optimizations even in very large models.
From the experimental results, the potential optimization significantly improves the training effect of GAN.
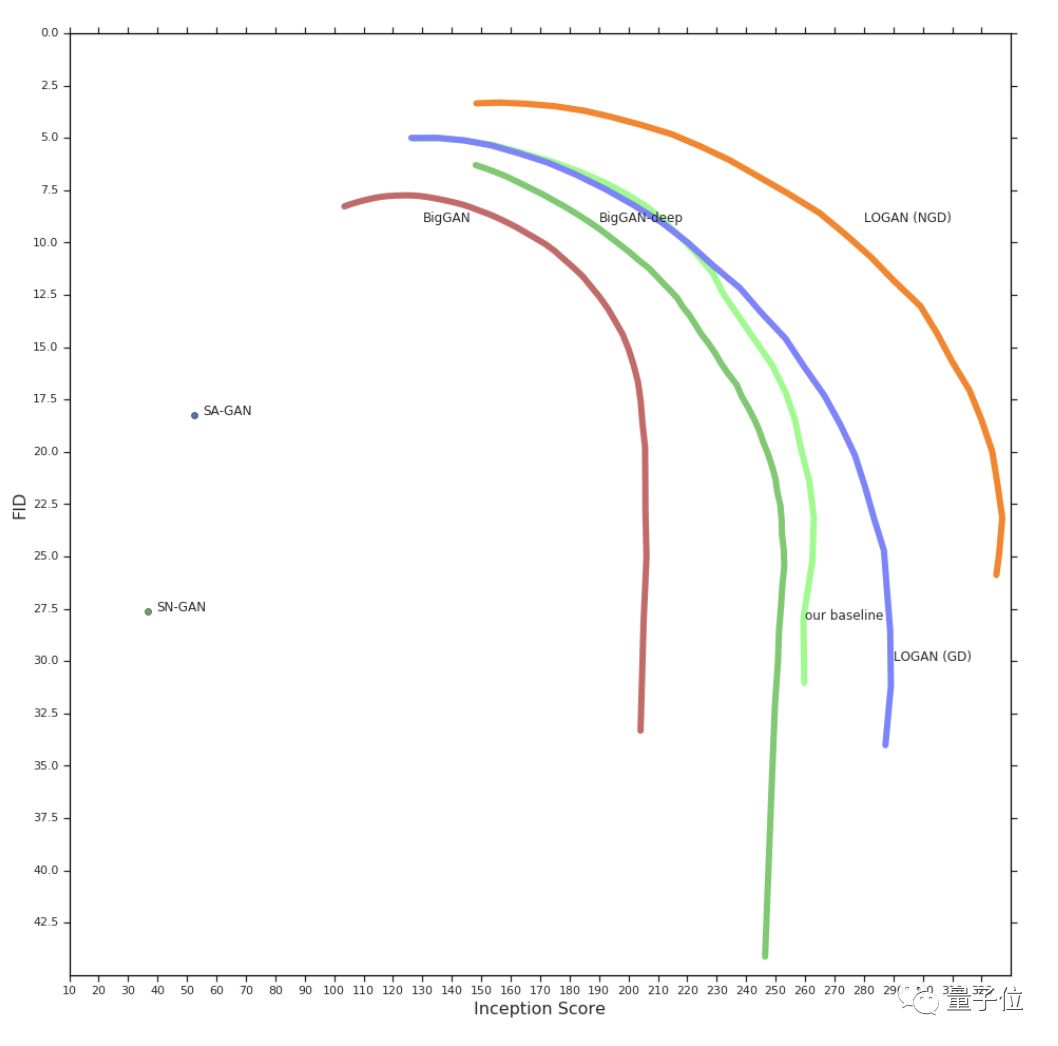
Using the same architecture and number of parameters as the BigGAN-deep baseline, LOGAN performs better on FID and IS.

However, during training, LOGAN is 2 to 3 times slower than BigGAN due to the extra forward and backward propagation.
Leading Chinese leader
The first work is Yan Wu, a research scientist at DeepMind.
He won Cambridge University in 2019He has a PhD degree in computational neuroscience, and entered DeepMind in 16 years.

The other authors of the paper are Dr. Jeff Donahue who graduated from UC Berkeley.
Dr. David Balduzzi, a graduate in mathematics from the University of Chicago.
Karen Simonyan, founder of Vision Factory.
And Timothy Lillicrap, a visiting professor at London College University and a PhD in system neuroscience from Queens University.
Portal:
Paper address: https://arxiv.org/abs/1912.00953
Related papers:
SGA: https://arxiv.org/abs/1802.05642CSGAN: https://arxiv.org/abs/1901.03554
Cover image from pexels