The investigation and analysis of open questions are huge, but now there is an antidote.
Editor’s note: This article comes from WeChat public account ” All Media School “ (ID: quanmeipai), author Tencent Media.
In the era of the Big Bang, rich data resources are treasures to be discovered, but they are also likely to become a source of stress.
As the media increasingly conducts content innovation and product exploration, data surveys that can reflect users’ emotional attitudes have become an important criterion for testing the effectiveness of innovation.

Maass Media is a data analysis cooperation agency introduced by the Guardian US Mobile Innovation Lab to help the Guardian gain a deeper understanding of users.
Previously, an article entitled Analysis Without Benchmarks: An Approach for Measuring the Success of Mobile Innovation Projects introduced Maass Media and Labs working together on users The specific operation of investigation and analysis. For example, in 2016, in order to test users ‘attitudes to different news formats on mobile phones, they took the presidential election as an opportunity and launched experiments on users’ response to real-time results push.

In the user survey, a feature of Maass Media is to provide a lot of open-ended questions. These open-ended questions can help investigators better understand the user’s deep psychology and avoid some of the disadvantages of closed-ended questions. However, open-ended questionsA huge amount of feedback information, if analyzed manually, the efficiency will be very low. How to solve this problem?
In this issue, All Media Group (ID: quanmeipai) exclusively compiles the latest Medium article. Let’s look at how to use algorithms to solve the analysis problem that contains a lot of non-standard data.
The answer is here: natural language algorithms
In order to more accurately measure the effectiveness of the new experiment, Maass Media and the laboratory attach great importance to the emotions and feelings of users, and want to find out whether the user’s feedback is positive or not through a survey of the feedback from the experiment subjects.
Therefore, in addition to objective multiple choice questions, there will be an open-ended question at the end of the user questionnaire: “Do you have anything else to tell us about this experiment?”
By encouraging open-ended answers, users can provide more forms of feedback to the survey, thereby complementing the closed-ended question. It can be said that open-ended questions provide a blind spot supplement for user feedback for user surveys.

Early, during the collection of survey data on the mobile end, Maass Media could complete the analysis through manual reading and manual classification due to the relatively small number of surveys. However, as the number of users increases and the number of responses to open-ended questions reaches tens of thousands, this approach becomes too inefficient. At the same time, due to the existence of subjectivity, each person’s understanding and classification of answers are also very different.
Maass Media pointed out that a new analysis method needs to be found, which can speed up the data analysis process and make the processing standards consistent.
“Our solution is to develop a sentiment analysis algorithm using natural language processing (NLP),” said Lynette Chen, senior digital analyst at Maass Media.

5 hours by hand, 5 minutes by algorithm
Natural language processing is computationOne of the effective methods of analyzing qualitative data by computer program. With a suitable model, based on a large amount of text data, investigators can perform sentiment analysis through algorithms, and quickly complete the analysis of respondents’ emotional reactions and opinions on a specific topic.
“Providing a reliable NLP solution for content analysis can not only reduce the time and effort of manual processing, but also effectively reduce the subjective bias in previous analysis.” Chen said.
Although there are many mature models for reference, Maass Media and the laboratory decided to build an independent model from scratch. Then, they trained the model based on different data sets to compare and analyze the success rate of the model. After three model iterations, they got a relatively perfect solution.
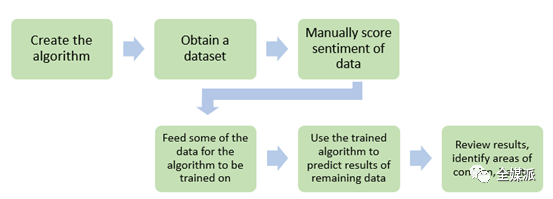
Model creation process
Based on the own model, after comparing the own dataset with the public dataset, the researchers found that the algorithm of the first iteration did not perform well on the public dataset, because the internal and external datasets were not effective for sentiment words. The way of labeling is not the same. After the second or third iteration, they borrowed the VADER algorithm model and obtained good results.
“The VADER algorithm was created by researchers at Georgia Institute of Technology and is crowdsourced (Crowdsourcing: The practice of obtaining the ideas, services, or content contributions from a broad group, especially the online community.) Continuous retraining This model trains a much wider dataset that includes user ratings for a series of words, emoji, slang, and acronyms. ”Lynette Chen introduced,“ After analysis, we decided to use this instead. Algorithm framework instead of using our own primitive basis algorithm, because it allows us to accurately analyze a larger range of words. “

After the algorithm is stable and mature, by using natural language processing, the time required to mark and count user non-standardized answers is greatly reduced.between. “If we manually read and manually tag a user’s sentiment and attitude data about media push during the election, this work could take about 5 hours.” Chen said, but with natural language processing algorithms, it can take less than 5 minutes. Complete the job within the time.
Although it has experienced various “pain” trials, Maass Media believes that developing NLP solutions is a valuable investment. Although the construction of this process is time-consuming, the results can significantly reduce data Time required for analysis.
“But this requires a highly skilled team, and iteratively iterates the algorithm to improve compatibility and accuracy.” Chen said.
Original link:
https://medium.com/the-guardian-mobile-innovation-lab/more-data-less-work-experimenting-with-natural-language-processing-for-faster-survey-analysis-d1665200d8e4 p>